概述
Python 有三种方法解析XML:SAX,DOM以及 ElementTree:
DOM:DOM 方式会将整个 XML 读入内存,在内存中解析成一个树,通过对树的操作来操作 XML,该方式占用内存较大,解析速度较慢。
SAX:SAX 方式逐行扫描 XML 文档,边扫描边解析,占用内存较小,速度较快,缺点是不能像 DOM 方式那样长期留驻在内存,数据不是长久的,事件过后,若没保存数据,数据会丢失。
ElementTree:ElementTree 方式几乎兼具了 DOM 方式与 SAX 方式的优点,占用内存较小、速度较快、使用也较为简单。
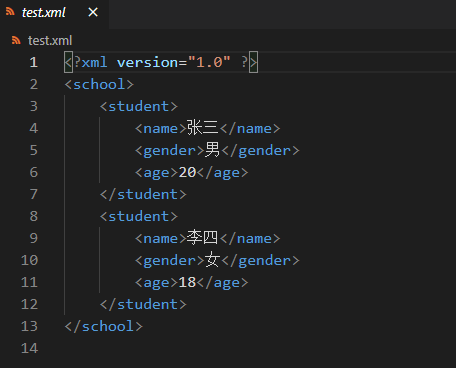
写入
1 | from xml.etree import ElementTree as et |
结果:
解析
DOM方式解析
1 | from xml.dom.minidom import parse |
SAX方式解析
1 | import xml.sax |
ElementTree方式解析
1 | import xml.etree.ElementTree as et |
参考: