Docker容器进入的方式
1.使用docker exec进入Docker容器
docker在1.3.X版本之后还提供了一个新的命令exec用于进入容器,这种方式相对更简单一些,下面我们来看一下该命令的使用:
1 | sudo docker exec --help |
1 | [root@localhost toor]# sudo docker exec --help |
1 | [root@localhost toor]# docker exec -it a46fa8852e07 /bin/bash |
参考:
docker在1.3.X版本之后还提供了一个新的命令exec用于进入容器,这种方式相对更简单一些,下面我们来看一下该命令的使用:
1 | sudo docker exec --help |
1 | [root@localhost toor]# sudo docker exec --help |
1 | [root@localhost toor]# docker exec -it a46fa8852e07 /bin/bash |
参考:
注:root下操作
1 | adduser testuser #新建testuser 用户 |
新创建的用户并不能使用sudo命令,需要给他添加授权。
sudo命令的授权管理是在sudoers文件里的。可以看看sudoers
1 | [root@localhost Desktop]# sudoers |
找到这个文件位置之后再查看权限:
1 | [root@localhost Desktop]# ls -l /etc/sudoers |
只有只读的权限,如果想要修改的话,需要先添加w权限:
1 | [root@localhost Desktop]# chmod -v u+w /etc/sudoers |
然后就可以添加内容了,在下面的一行下追加新增的用户:
1 | ## Allow root to run any commands anywhere |
wq保存退出,这时候要记得将写权限收回:
1 | [root@localhost Desktop]# chmod -v u-w /etc/sudoers |
这时候使用新用户登录,使用sudo
1 | groupadd testgroup |
1 | useradd -g testgroup testuser |
注::-g 所属组
1 | usermod -G groupname username |
1 | userdel testuser |
用户列表文件:/etc/passwd
用户组列表文件:/etc/group
查看系统中有哪些用户:cut -d : -f 1 /etc/passwd
查看可以登录系统的用户:cat /etc/passwd | grep -v /sbin/nologin | cut -d : -f 1
查看用户操作:w命令(需要root权限)
查看某一用户:w 用户名
查看登录用户:who
查看用户登录历史记录:last
参考:
https://www.linuxidc.com/Linux/2016-11/137549.htm
Docker项目提供了构建在Linux内核功能之上,协同在一起的的高级工具。其目标是帮助开发和运维人员更容易地跨系统跨主机交付应用程序和他们的依赖。Docker通过Docker容器,一个安全的,基于轻量级容器的环境,来实现这个目标。这些容器由镜像创建,而镜像可以通过命令行手工创建或 者通过Dockerfile自动创建。
Dockerfile是由一系列命令和参数构成的脚本,这些命令应用于基础镜像并最终创建一个新的镜像。它们简化了从头到尾的流程并极大的简化了部署工作。Dockerfile从FROM命令开始,紧接着跟随者各种方法,命令和参数。其产出为一个新的可以用于创建容器的镜像。
一般而言,Dockerfile 的内容分为四个部分:基础镜像信息、维护者信息、镜像操作指令和容器启动时执行指令。
1 | # This dockerfile uses the Ubuntu image |
FROM命令可能是最重要的Dockerfile命令。该命令定义了使用哪个基础镜像启动构建流程。基础镜像可以为任意镜像。如果基础镜像没有被发现,Docker将试图从Docker image index来查找该镜像。FROM命令必须是Dockerfile的首个命令。
1 | # Usage: FROM [image name] |
声明作者;这个命令放在Dockerfile的起始部分,虽然理论上它可以放置于Dockerfile的任意位置。这个命令用于声明作者,并应该放在FROM的后面。
注意:MAINTAINER 指令已经被抛弃,建议使用 LABEL 指令。
1 | # Usage: MAINTAINER [name] |
格式为:
1 | LABEL <key>=<value> <key>=<value> <key>=<value> ... |
LABEL 指令为镜像添加标签。一个 LABEL 就是一个键值对。
下面是一些例子:
1 | LABEL "com.example.vendor"="ACME Incorporated" |
我们可以给镜像添加多个 LABEL,需要注意的是,每条 LABEL 指令都会生成一个新的层。所以最好是把添加的多个 LABEL 合并为一条命令:
1 | LABEL multi.label1="value1" multi.label2="value2" other="value3" |
也可以写成这样:
1 | LABEL multi.label1="value1" \ |
如果新添加的 LABEL 和已有的 LABEL 同名,则新值会覆盖掉旧值。
我们可以使用 docker inspect 命令查看镜像的 LABEL 信息。
1 | 有两种格式,分别为: |
RUN命令是Dockerfile执行命令的核心部分。它接受命令作为参数并用于创建镜像。不像CMD命令,RUN命令用于创建镜像(在之前commit的层之上形成新的层)。
前者将在 shell 终端中运行命令,即 /bin/sh -c,后者则使用 exec 执行。指定使用其他终端可以通过第二种方式实现,例如 RUN [“/bin/bash”, “-c”, “echo hello”]。
每条 RUN 指令将在当前镜像的基础上执行指定命令,并提交为新的镜像。当命令较长时可以使用 \ 来换行。
1 | # Usage: RUN [command] |
支持三种格式:
1 | CMD [“executable”, “param1”, “param2”] 使用 exec 执行,推荐方式。 |
指定启动容器时执行的命令,每个 Dockerfile 只能有一条 CMD 命令。如果指定了多条 CMD 命令,只有最后一条会被执行。如果用户在启动容器时指定了要运行的命令,则会覆盖掉 CMD 指定的命令。
和RUN命令相似,CMD可以用于执行特定的命令。和RUN不同的是,这些命令不是在镜像构建的过程中执行的,而是在用镜像构建容器后被调用。
1 | # Usage 1: CMD application "argument", "argument", .. |
格式为:
1 | EXPOSE <port> [<port>…] |
告诉 Docker 服务,容器需要暴露的端口号,供互联系统使用。在启动容器时需要通过 -P 参数让 Docker 主机分配一个端口转发到指定的端口。使用 -p 参数则可以具体指定主机上哪个端口映射过来。
1 | # Usage: EXPOSE [port] |
ENV命令用于设置环境变量。这些变量以”key=value”的形式存在,并可以在容器内被脚本或者程序调用。这个机制给在容器中运行应用带来了极大的便利。
1 | # Usage: ENV key value |
格式为:
1 | ADD <src> <dest> |
ADD命令有两个参数,源和目标。它的基本作用是从源系统的文件系统上复制文件到目标容器的文件系统。如果源是一个URL,那该URL的内容将被下载并复制到容器中。其中 <src> 可以是 Dockerfile 所在目录的一个相对路径(文件或目录);也可以是一个 URL;还可以是一个 tar 文件(自动解压为目录)。
1 | # Usage: ADD [source directory or URL] [destination directory] |
格式:
1 | COPY <src> <dest> |
复制本地主机的 <src> (为 Dockerfile 所在目录的相对路径,文件或目录) 为容器中的 <dest>。目标路径不存在时,会自动创建。当使用本地目录为源目录时,推荐使用 COPY。
有两种格式:
1 | ENTRYPOINT [“executable”, “param1”, “param2”] |
配置容器启动后执行的命令,并且不可被 docker run 提供的参数覆盖。
每个 Dockerfile 中只能有一个 ENTRYPOINT,当指定多个时,只有最后一个起效。
ENTRYPOINT 帮助你配置一个容器使之可执行化,如果你结合CMD命令和ENTRYPOINT命令,你可以从CMD命令中移除“application”而仅仅保留参数,参数将传递给ENTRYPOINT命令。
1 | # Usage: ENTRYPOINT application "argument", "argument", .. |
格式为:
1 | VOLUME ["/data"] |
也可以使用 VOLUME 指令添加多个数据卷:
1 | VOLUME ["/data1", "/data2"] |
创建一个可以从本地或其他容器挂载的挂载点,一般用来存放数据库和需要保持的数据等。
VOLUME命令用于让你的容器访问宿主机上的目录。
1 | # Usage: VOLUME ["/dir_1", "/dir_2" ..] |
指定运行容器时的用户名或 UID,后续的 RUN 也会使用指定用户。当服务不需要管理员权限时,可以通过该命令指定运行用户。并且可以在之前创建所需要的用户,例如:RUN groupadd -r postgres && useradd -r -g postgres postgres。
1 | # Usage: USER [UID] |
格式为:
1 | WORKDIR /path/to/workdir |
为后续的 RUN、CMD、ENTRYPOINT 指令配置工作目录。可以使用多个 WORKDIR 指令,后续命令如果参数是相对路径,则会基于之前命令指定的路径。例如:
1 | # Usage: WORKDIR /path |
格式为:
1 | ONBUILD [INSTRUCTION] |
配置当所创建的镜像作为其他新创建镜像的基础镜像时,所执行的操作指令。例如,Dockerfile 使用如下的内容创建了镜像 image-A。
1 | ONBUILD ADD . /app/src |
如果基于 image-A 创建新的镜像时,新的 Dockerfile 中使用 FROM image-A 指定基础镜像时,会自动执行 ONBUILD 指令内容,等价于在后面添加了两条指令。
1 | FROM image-A |
编写完成 Dockerfile 之后,可以通过 docker build 命令来创建镜像。
使用Dockerfiles和手工使用Docker Daemon运行命令一样简单。脚本运行后输出为新的镜像ID。
1 | # Build an image using the Dockerfile at current location |
基本的格式为 docker build [选项] 路径,该命令将读取指定路径下(包括子目录)的 Dockerfile ,并将该路径下所有内容发送给 docker 服务端,由服务端来创建镜像。因此一般建议放置 Dockerfile 的目录为空目录。
另外,可以通过 .dockerignore 文件来让 docker 忽略路径下的目录和文件。 要指定镜像的标签信息,可以通过 -t 选项来实现。
例如,指定 Dockerfile 所在路径为 /tmp/docker_builder/,并且希望生成镜像标签为 build_repo/first_image,可以使用下面的命令:
1 | sudo docker build -t build_repo/first_image /tmp/docker_builder/ |
参考:
http://www.cnblogs.com/sparkdev/p/6357614.html
https://yeasy.gitbooks.io/docker_practice/content/introduction/what.html
1 | $ sudo yum install -y yum-utils \ |
启动
1 | sudo systemctl start docker |
验证是否成功
1 | sudo docker run hello-world |
推荐安装1.10.0以上版本的Docker客户端
针对Docker客户端版本大于1.10.0的用户
您可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器:
1 | sudo mkdir -p /etc/docker |
或者使用ttps://registry.docker-cn.com
1 | sudo yum remove docker-ce |
1 | sudo rm -rf /var/lib/docker |
您必须手动删除任何定义配置文件。
1 | wget https://dl.eff.org/certbot-auto |
1 | ./certbot-auto certonly -d *.域名 --manual --preferred-challenges dns --server https://acme-v02.api.letsencrypt.org/directory |
按照提示依次填写邮箱地址,同意服务条款,绑定IP就行了。
面这一步很关键,需要你配置你的域名TXT记录,以校验域名所有权,也就是判断证书申请者是不是该域名的拥有者。
1 | Please deploy a DNS TXT record under the name |
在添加txt记录到你的域名之前,切勿点击回车键。
登陆域名解析控制台(阿里云),添加一条TXT记录:
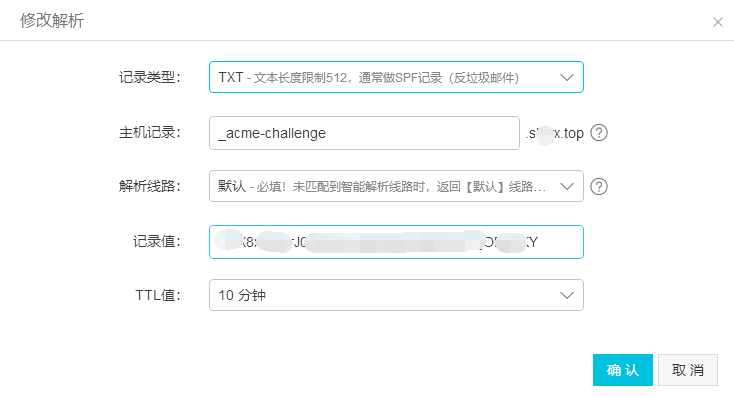
执行命令:dig -t txt _acme-challenge.shiyx.top
1 | ubuntu@ip-172-31-16-20:~$ dig -t txt _acme-challenge.shiyx.top |
确认生效后,按回车键继续
1 | IMPORTANT NOTES: |
证书申请完毕!证书和密钥保存在“/etc/letsencrypt/archive/”目录下
1 | ubuntu@ip-172-31-16-20:~$ sudo tree /etc/letsencrypt/archive |
官网:
https://certbot.eff.org/docs/using.html?highlight=renew#renewing-certificates
1 | sudo certbot renew |
Let’s Encrypt 证书的有效期只有 90 天,因此我们需要定期的对他进行续签,我们使用linux自带的cron来设定计划任务
1 | crontab -e |
注意,如果你是第一次运行 crontab 命令,它会问题使用哪一个编辑器,你可以根据自己的需要进行选择,我选择的是 vim-basic
1 | sudo crontab -e |
添加配置:
1 | 30 2 * * 1 sudo certbot renew |
上面的执行时间为:每周一半夜2点30分执行renew任务。
你可以在命令行执行sudo renew看看是否执行正常。
注:aws需要定义安全组,允许https入站规则
Webroot 的工作插件放置在一个特殊的文件/.well-known目录文档根目录下,它可以打开(通过Web服务器)内由让我们的加密服务进行验证。 根据配置的不同,你可能需要明确允许访问/.well-known目录。
为了确保该目录可供Let’s Encrypt进行验证,让我们快速更改我们的Nginx配置。编辑sudo vim /etc/nginx/sites-available/default文件,并将下面代码添加进去:
1 | location ~ /.well-known { |
1 | ## 检查测试配置文件是否正确 |
Nginx配置:
1 | server { |
另附https检查网站
hhttps://www.ssllabs.com/ssltest/analyze.html
参考:
https://www.lao-wang.com/?p=142
https://blog.guorenxi.com/43.html
https://segmentfault.com/a/1190000005797776
http://www.cnblogs.com/stulzq/p/8628163.html
1 | sudo apt-get install nginx |
Ubuntu安装之后的文件结构大致为:
1 | sudo /etc/init.d/nginx start |
或者
1 | sudo service nginx start |
1 | sudo service nginx stop |
1 | sudo nginx -t -c /etc/nginx/nginx.conf |
然后就可以访问了,http://localhost/,默认80端口
地址:
https://github.com/shadowsocks/shadowsocks
快速(异步I/O和事件驱动程序)
安全(所有的流量都经过加密算法加密,支持自定义算法)
支持移动客户端(专为移动设备和无线网络优化)
跨平台(可运行于包括PC,Mac,手机(Android和iOS)和路由器(OpenWrt)在内的多种平台上)
Debian / Ubuntu:
1 | sudo apt update |
CentOS:
1 | yum install python-setuptools && easy_install pip |
无论是centos系统还是ubuntu系统,shadowsocks配置都是一样的。
shadowsocks安装完毕后,可以查看使用ssserver命令进行查看
1 | ubuntu@ip-172-31-16-20:~$ ssserver -h |
which ssserver
1 | ubuntu@ip-172-31-16-20:~$ which ssserver |
1 | sudo mkdir /etc/shadowsocks |
启动:
1 | sudo ssserver -c /etc/shadowsocks/config.json -d start |
停止:
1 | sudo ssserver -c /etc/shadowsocks/config.json -d stop |
1 | sudo ssserver -p 443 -k password -m rc4-md5 |
如果要后台运行:
1 | sudo ssserver -p 443 -k password -m rc4-md5 --user nobody -d start |
如果要停止:
1 | sudo ssserver -d stop |
如果要检查日志:
1 | sudo less /var/log/shadowsocks.log |
参考官网链接:
https://docs.docker.com/install/linux/docker-ce/ubuntu/
1 | docker pull oddrationale/docker-shadowsocks |
1 | docker run --rm -d -p 8388:8388 oddrationale/docker-shadowsocks -s 0.0.0.0 -p 8388 -k 'paaassswwword' -m aes-256-cfb |
运行: docker ps
查看shadowsocks是否运行起来了,没问题的话就可以exit退出vps的登录了
停止容器:
1 | docker stop --time=20 container_name |
8388 服务器端的端口号,paaassswwword 是密码, aes-256-cfb 是加密方式
在aws ec2控制平台添加安全组规则-入站规则
自定义TCP规则,端口,任何位置
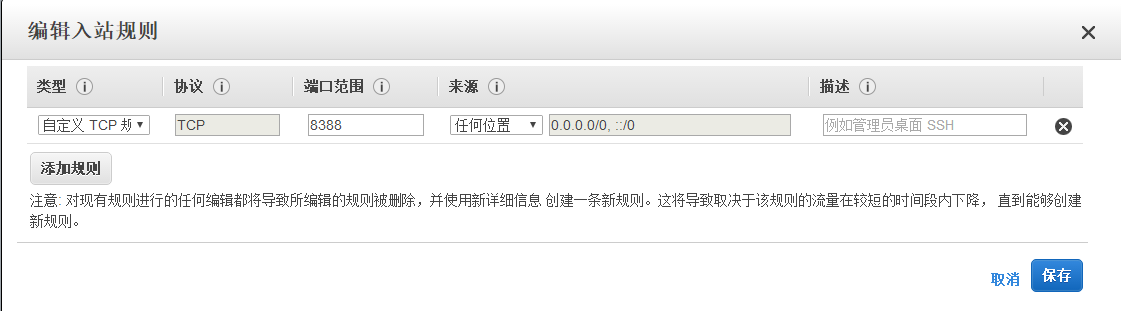
shadowsocks服务器搭建完毕后,我们现在来客户端连接shadowsocks服务器。
shadowsocks客户端有Windows版本和Linux版本
windows版本,我们可以从如下网址进行下载,如下:
https://github.com/shadowsocks/shadowsocks-windows/releases
下载完毕后,双击Shadowsocks.exe,在弹出框填入
Shadowsocks服务器的IP、Shadowsocks服务器端口,密码。
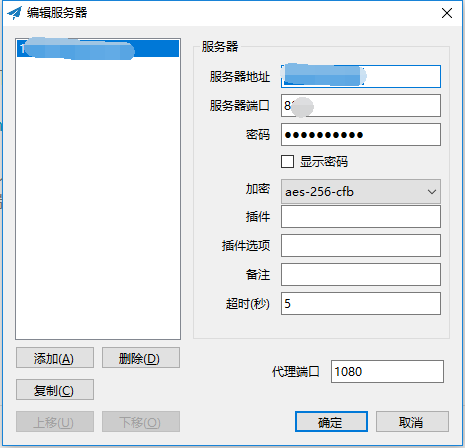
参考网址:
生产环境偶尔会出现一些异常问题,WinDbg 或 GDB 就是解决此类问题的利器。调试工具 WinDbg 如同医生的听诊器,是系统生病时做问题诊断的逆向分析工具,Dump 文件类似于飞机的黑匣子,记录着生产环境程序运行的状态。
本文主要介绍了调试工具 WinDbg 和抓包工具 ProcDump 的使用。
WinDbg 是在 Windows 平台下的、强大的用户态和内核态调试工具。相比较于 Visual Studio,它是一个轻量级的调试工具,所谓轻量级指的是它的安装文件大小较小,但是其调试功能,却比 VS 更为强大。
它的另外一个用途是可以用来分析 Dump 数据。WinDbg 是 Microsoft 公司免费调试器调试集合中的 GUI 的调试器,支持 Source 和 Assembly 两种模式的调试。
WinDbg 不仅可以调试应用程序,还可以进行 Kernel Debug。结合 Microsoft 的 Symbol Server,可以获取系统符号文件,便于应用程序和内核的调试。
WinDbg 支持的平台包括 x86、IA64、AMD64。虽然 WinDbg 也提供图形界面操作,但它最强大的地方还是有着强大的调试命令,一般情况会结合 GUI 和命令行进行操作,常用的视图有:局部变量、全局变量、调用栈、线程、命令、寄存器、白板等。其中“命令”视图是默认打开的。
DebugDiag 最初是为了帮助分析 IIS 的性能问题而开发的,它同样可以用于任何其他的进程。DebugDiag 工具主要用于帮助解决如挂起、 速度慢、 内存泄漏或内存碎片,和任何用户模式进程崩溃等问题。
该工具包括附加调试脚本,侧重于互联网信息服务(IIS)应用程序、 Web 数据访问组件、 COM+ 和相关 Microsoft 技术、SharePoint 和 .NET。它提供可扩展对象模型中的 COM 对象的形式,并具有一个内置的报告框架提供的脚本主机。它由 3 部分组成,包括调试服务、 调试器主机和用户界面。
ProcDump 是 System Internal 提供的一个专门用来监测程序 CPU 高使用率从而生成进程 Dump 文件的工具。ProcDump 可以根据系统的 CPU 使用率或者指定的性能计数器来针对特定进程生成一系列的 Dump 文件,以便调试者对事故原因进行分析。
1、WinDbg 下载
2、DebugDiag v2 Update 2 下载:https://www.microsoft.com/en-us/download/details.aspx?id=49924
3、ProcDump v9.0 下载:https://download.sysinternals.com/files/Procdump.zip
以下四种方式获取 Dump 文件:
C:\Program Files\Debugging Tools for Windows (x64)>adplus -hang -pn explorer.exe
-o D:\dumps
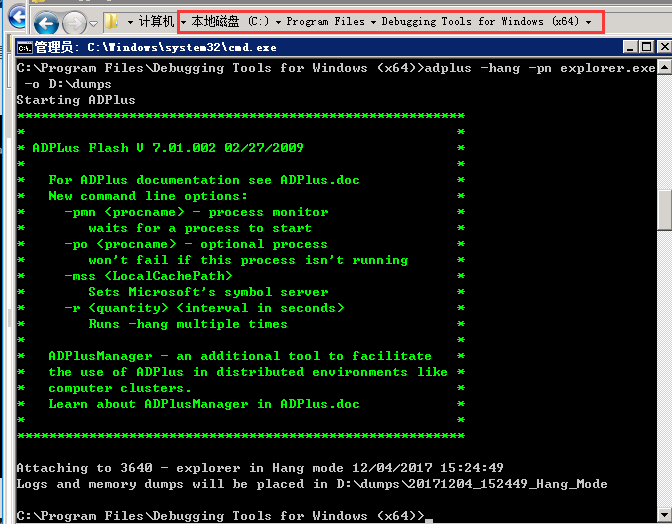
进入ProcDump目录,运行命令行:
1 | procdump [-a] [[-c|-cl CPU usage] [-u] [-s seconds]] [-n exceeds] |
实例:
1 | procdump -c 70 -s 5 -ma -n 3 w3wp |
注意:
配置 Idle Timeout = 20 min,即该进程在 20 分钟内没有任何请求的话就会自动结束,这种情况下 ProcDump 也会自动结束。需要重新运行命令。
因此如果目标程序存在这样的配置,需要暂时将该配置取消。
有些系统管理员希望能够运行该工具后退出用户 session,ProcDump 是做不到的,如果有这种需求可以考虑使用 DebugDiag。
在调试 High CPU 问题的时候经常用到的一个命令是!runaway,但是有些时候!runway 在 ProcDump 抓取 Dump 文件的过程中运行不出来,报错信息如下:
0:000> !runaway ERROR: !runaway: extension exception 0x80004002. “Unable to get thread times - dumps may not have time information”
解决方法是将 Debugging Tools for Windows (WinDbg) 安装目录下的 dbghelp.dll 拷贝到 procdump.exe 所在目录下,然后再运行命令抓取 Dump。
操作步骤如下:
符号表是 WinDbg 关键的“数据库”,如果没有它,WinDbg 基本上就是个废物,无法分析更多问题。所以使用 WinDbg 设置符号表,是必须要走的一步。
a、运行 WinDbg 软件,然后按【Ctrl+S】弹出符号表设置窗。
b、将符号表地址:SRVC:\Symbols
http://msdl.microsoft.com/download/symbols 粘贴在输入框中(不能换行),点击确定即可。点击确定之前,请先确认红色字的文件夹是否已被新建。
注:红色字C:\Symbols表示符号表本地存储路径,建议固定路径,可避免符号表重复下载。
使用【Ctrl+D】快捷键,或者点击 WinDbg 界面上的【File=>Open Crash Dump…】按钮,来打开一个 Dump 文件。
当你想打开第二个 Dump 文件时,可能因为上一个分析记录未清除,导致无法直接分析 Dump 文件,此时你可以使用快捷键【Shift+F5】来关闭上一个对 Dump 文件的分析记录。
SOS does not support the current target architecture
这个错误的原因是用了32位的任务管理器抓的32位的dump文件。
需要用64位的任务管理器抓32位的dump文件(C:\Windows\SysWOW64\taskmgr.exe)
1 | .loadby sos clr //首先加载sos |
将dump文件拖入windbg
执行.loadby sos clr或.loadby sos mscorwks加载模块
执行!analyze -v 进行异常分析
Open Executeable..
执行 sxe ld:clrjit
执行 g
执行.loadby sos clr
1 | .sympath // 检查sympath是否正确 |
参考:
https://www.cnblogs.com/sheng-jie/p/9503650.html
http://mp.weixin.qq.com/s/R6TrIlxqJVgApFP-V2r0GA
http://blog.csdn.net/beanjoy/article/details/39203259
http://www.cnblogs.com/Clingingboy/archive/2013/03/26/2983166.html
netstat -nap #会列出所有正在使用的端口及关联的进程/应用
lsof -i :portnumber #portnumber要用具体的端口号代替,可以直接列出该端口听使用进程/应用
netstat -lntp
netstat -lnp|grep 88 #88请换为你的apache需要的端口,如:80
ps 1777
kill -9 1777 #杀掉编号为1777的进程(请根据实际情况输入)
service httpd start #启动apache
开启端口:
1 | firewall-cmd --zone=public --add-port=6379/tcp --permanent |
命令含义:
1 | --zone #作用域 |
重启防火墙
1 | firewall-cmd --reload #重启防火墙 |
1 | [root@localhost toor]# cd /etc/sysconfig/network-scripts |
示例:
1 | TYPE=Ethernet |
重启网络服务
1 | service network restart |
若出现重启失败的话,可以试着把ifcfg-eno文件里的DEVICE一行删除试试
注: root账户安装
1 | yum install https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm |
1 | yum install postgresql96 ##客户端包## |
安装过程出现问题,可能会导致初始化数据库错误错误,如下:
解决方法:重新执行命令 yum install postgresql96-server
1 | [root@iz2zeii3e4srrxcoy1gbubz ~]# /usr/pgsql-9.6/bin/postgresql96-setup initdb |
1 | /usr/pgsql-9.6/bin/postgresql96-setup initdb |
PostgreSQL 安装完成后,会建立一下‘postgres’用户,用于执行PostgreSQL,数据库中也会建立一个’postgres’用户,默认密码为自动生成,需要在系统中改一下。
1 | su - postgres ##切换用户,执行后提示符会变为 '-bash-4.2$' |
1 | vi /var/lib/pgsql/9.6/data/postgresql.conf |
修改#listen_addresses = ‘localhost’ 为 listen_addresses=’*’
当然,此处‘*’也可以改为任何你想开放的服务器IP
1 | vi /var/lib/pgsql/9.6/data/pg_hba.conf |
修改如下内容,信任指定服务器连接
1 | # IPv4 local connections: |
CentOS 防火墙中内置了PostgreSQL服务,配置文件位置在
/usr/lib/firewalld/services/postgresql.xml,
我们只需以服务方式将PostgreSQL服务开放即可。
1 | firewall-cmd --add-service=postgresql --permanent 开放postgresql服务 |
1 | systemctl restart postgresql-9.6.service |
本地服务器连接数据库出现以下错误:
1 | OperationalError: FATAL: Ident authentication failed for user “dbuser” |
出现这个错误的原因还是在于上面pg_hba.conf 文件的设置,Debian系(包括ubuntu)默认的pg_hba.conf 文件对于
localhost本地机器的数据库访问方式是ident,它指的是只有Linux shell用户通过同名的postgreSQL 用户才能访问,
也就是pg超级用户postgres 只能由linux 用户postgres 登录后操作。
“postgres”的问题,有两种解决方法:
在执行$ python manage.py shell之前先$su postgres 切换为postgres 用户
修改pg_hba.conf 的客户端访问设置,将laocal 的访问由ident 改为trust,如:
1 | # TYPE DATABASE USER CIDR-ADDRESS METHOD |
修改完pg_hba.conf设置记得重启pg。安装了pg_ctl 也可以用pg_ctl reload。
参考:
http://www.jianshu.com/p/7e95fd0bc91a
http://www.cnblogs.com/mchina/archive/2012/06/06/2539003.html
Linux tar(英文全拼:tape archive )命令用于备份文件。
语法
1 | tar [-ABcdgGhiklmMoOpPrRsStuUvwWxzZ][-b <区块数目>][-C <目的目录>][-f <备份文件>][-F <Script文件>][-K <文件>][-L <媒体容量>][-N <日期时间>][-T <范本文件>][-V <卷册名称>][-X <范本文件>][-<设备编号><存储密度>][--after-date=<日期时间>][--atime-preserve][--backuup=<备份方式>][--checkpoint][--concatenate][--confirmation][--delete][--exclude=<范本样式>][--force-local][--group=<群组名称>][--help][--ignore-failed-read][--new-volume-script=<Script文件>][--newer-mtime][--no-recursion][--null][--numeric-owner][--owner=<用户名称>][--posix][--erve][--preserve-order][--preserve-permissions][--record-size=<区块数目>][--recursive-unlink][--remove-files][--rsh-command=<执行指令>][--same-owner][--suffix=<备份字尾字符串>][--totals][--use-compress-program=<执行指令>][--version][--volno-file=<编号文件>][文件或目录...] |
参数:
1 | -A或--catenate 新增文件到已存在的备份文件。 |
文件操作:
1 | ls # 查看目录中的文件 |
压缩与解压缩:
1 | tar -zcvf nginx.tar.gz nginx # 压缩nginx文件夹 |
参考:
1 | # 使用touch创建空文件 |
注:提前更新Docker镜像源
1 | FROM jenkins |
注:可能出现
1 | [root@localhost Desktop]# curl -L https://github.com/docker/compose/releases/download/1.16.1/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose |
需要运行以下命令更新:
1 | yum update nss curl nss-util nspr |
等待时间可能有点长,请耐心等待
运行结果:
1 | [root@localhost Desktop]# docker build . -t auto-jenkins |
出现以上 Successfully 内容代表安装Jenkins成功
需要先创建一个Jenkins的配置目录,并且挂载到docker 里的Jenkins目录下
1 | mkdir -p /var/jenkins_home |
运行
1 | docker run --name jenkins -p 8080:8080 -p 50000:50000 \ |
第一行构建一个名称为jenkins的容器,需要使用的 8080 跟 50000 端口,-p 是容器运行开放端口
第二行将宿主机上的 docker.sock 挂载到容器中的相应位置,使得容器中的 docker cli 能跟宿主机的 docker 通信
第三行将宿主机上面的 docker 命令行工具挂载到容器中,使 jenkins 用户能够执行 docker 命令
第四行挂载我们之前创建的配置文件存放目录到 jenkins 用户的 home(对的,jenkins 用户的 home 目录在 /var 下面),建立宿主机的配置目录,挂载进docker容器里,这样容器里的Jenkins配置目录文件就会映射出来
第五行:使用auto-jenkins Image 并且后台启动
运行完这条指令后,出现一串很长的字符串以后,我们的jenkins已经成功启动,可以访问本机的 8080 端口来登录 Jenkins
通过命令docker ps查看运行的镜像
1 | [root@localhost Desktop]# docker ps |
删除docker
1 | docker rm -f jenkins |
进入容器内
1 | docker exec -it jenkins /bin/bash |
查看密码:
1 | cat /var/jenkins_home/secrets/initialAdminPassword |
1 | oot@localhost Desktop]# docker exec -it jenkins /bin/bash |
复制输出的内容,粘贴到Administrator password,输入 exit 退出容器,此时进行下一步你会看到此界面,点击 Install suggested plugins
重启:
1 | docker restart jenkins |
最后,安装推荐插件
忘记管理员密码
1 | [root@localhost Desktop]# cd /var/jenkins_home/users/admin/ |
把<passwordHash>节点的内容(图中黑色的那一串)换成
#jbcrypt:$2a$10$DdaWzN64JgUtLdvxWIflcuQu2fgrrMSAMabF5TSrGK5nXitqK9ZMS
重启,默认密码为:111111
参考网址:
http://www.cnblogs.com/LongJiangXie/p/7517909.html
1、首先去官网下载zookeeper的包 zookeeper-3.4.10.tar.gz
2、用FTP文上传到/usr/local下
3、解压文件 tar -zxvf zookeeper-3.4.10.tar.gz
4、在conf文件夹下新建zoo.cfg文件,或者使用里面自带的zoo_sample.cfg,重新拷贝
cp zoo_sample.cfg zoo.cfg
zoo.cfg文件内容:
1 | tickTime=2000 |
5、运行server脚本
需要在root账户下启动:
1 | [root@localhost zookeeper-3.4.10]# ./bin/zkServer.sh start |
6、Server启动之后, 就可以启动client连接server了, 执行脚本:
1 | [root@localhost zookeeper-3.4.10]# ./bin/zkCli.sh -server localhost:4180 |
7,检查状态
1 | [root@localhost zookeeper-3.4.10]# ./bin/zkServer.sh start |
8,停止
1 | [root@localhost zookeeper-3.4.10]# ./bin/zkServer.sh stop |
所谓伪集群, 是指在单台机器中启动多个zookeeper进程, 并组成一个集群. 以启动3个zookeeper进程为例
1 | [toor@localhost zookeeper]$ su root |
1,zookeeper-3.4.10-1中的zoo.cfg文件
1 | tickTime=2000 |
2,zookeeper-3.4.10-2中的zoo.cfg文件
1 | tickTime=2000 |
3,zookeeper-3.4.10-3中的zoo.cfg文件
1 | tickTime=2000 |
发现只有dataDir和dataLogDir还有clientPort这三个参数不一致,其他参数完全一致。
配置myid
在这三个datadir配置的路径下/Users/zookeeper0、1、2上增加myid文件,里面依次填上0、1、2。
数字0、1、2和每个conf/zoo.cfg中的server.0、server.1、server.2的数字一一对应,让zookeeper知道你是哪个server
依次启动zookeeper节点服务
1 | ./bin/zkServer.sh start |
检查状态
1 | ./bin/zkServer.sh status |
客户端连接
1 | ./bin/zkCli.sh -server localhost:4180 |
看到输出显示有下列信息,表示启动,配置成功!
1 | Welcome to ZooKeeper! |
集群模式, 各server部署在不同的机器上, 因此各server的conf/zoo.cfg文件可以完全一样(是所有都一样)
他们的zookeeper的conf下的zoo.cfg文件为:
1 | tickTime=2000 |
部署了3台zookeeper server, 分别部署在192.168.1.130, 192.168.1.131, 192.168.1.132上。
各server的dataDir目录下的myid文件中的数字必须不同。
192.168.1.130 server的myid为1
192.168.1.131 server的myid为2
192.168.1.132 server的myid为3
至此,所有的安装与部署就都搞定了。
在准备好相应的配置之后,可以直接通过zkServer.sh 这个脚本进行服务的相关操作
zoo.cfg配置详解:
tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,每个tickTime 时间就会发送一个心跳。
dataDir:Zookeeper 保存数据的目录,默认情况下,Zookeeper 将写数据的日志文件也保存在这个目录里。
clientPort:客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
initLimit:Leader和Follower初始化连接时最长能忍受多少个心跳时间间隔数。总的时间长度就是 5*2000=10 秒。
syncLimit:Leader 与 Follower之间发送消息,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4 秒。
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器;B 是这个服务器的 ip 地址;C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口;D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
myid文件:
除了修改 zoo.cfg 配置文件,集群模式下还要配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面就有一个数据就是 A 的值,Zookeeper 启动时会读取这个文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个server。
server.1=10.1.39.43:2888:3888,很多人不理解为啥后面有两个端口?解释一下:
2888:标识这个服务器与集群中的leader服务器交换信息的端口
3888:leader挂掉时专门用来进行选举leader所用的端口
参考:
吞吐率(Requests per second)
概念:服务器并发处理能力的量化描述,单位是reqs/s,指的是某个并发用户数下单位时间内处理的请求数。某个并发用户数下单位时间内能处理的最大请求数,称之为最大吞吐率。
计算公式:总请求数 / 处理完成这些请求数所花费的时间,即
Request per second = Complete requests / Time taken for tests
并发连接数(The number of concurrent connections)
概念:某个时刻服务器所接受的请求数目,简单的讲,就是一个会话。
并发用户数(The number of concurrent users,Concurrency Level)
概念:要注意区分这个概念和并发连接数之间的区别,一个用户可能同时会产生多个会话,也即连接数。
用户平均请求等待时间(Time per request)
计算公式:处理完成所有请求数所花费的时间/ (总请求数 / 并发用户数),即
Time per request = Time taken for tests /( Complete requests / Concurrency Level)
服务器平均请求等待时间(Time per request: across all concurrent requests)
计算公式:处理完成所有请求数所花费的时间 / 总请求数,即
Time taken for / testsComplete requests
可以看到,它是吞吐率的倒数。
同时,它也=用户平均请求等待时间/并发用户数,即
Time per request / Concurrency Level
解压压缩包,进入到httpd-2.4.25-win64-VC14\Apache24\bin目录下,
打开命令行,输入命令
1 | ab -n 100 -c 10 http://baidu.com/ |
其中-n表示请求数,-c表示并发数
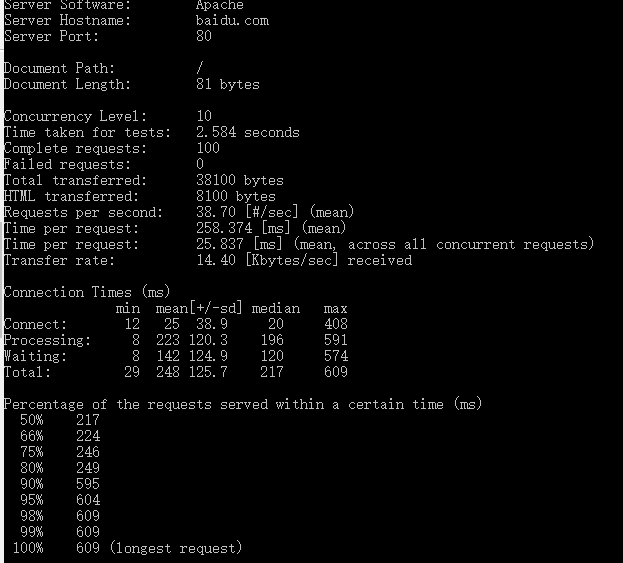
显示服务器为apache,域名,端口;
1 | Server Software: Apache |
所在位置“/”,文档的大小为338436 bytes(此为http响应的正文长度)
1 | Document Path: / |
1 | Concurrency Level: 10 |
1 | //并发请求数 |
1 | Connection Times (ms) |
这段是每个请求处理时间的分布情况,50%的处理时间在217ms内,66%的处理时间在224ms内…,重要的是看90%的处理时间
1 | Percentage of the requests served within a certain time (ms) |
有时候进行压力测试需要用户登录,怎么办?
请参考以下步骤:
先用账户和密码登录后,用开发者工具找到标识这个会话的Cookie值(Session ID)记下来
如果只用到一个Cookie,那么只需键入命令:
ab -n 100 -C key=value http://baidu.com/
如果需要多个Cookie,就直接设Header:
ab -n 100 -H “Cookie: Key1=Value1; Key2=Value2” http://baidu.com/
同类型的压力测试工具还有:webbench、siege、http_load等
参考: