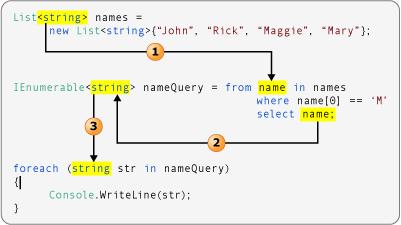
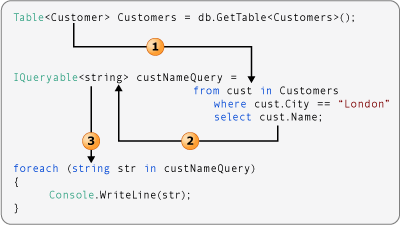
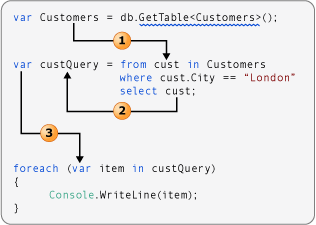
通过对象和集合初始值设定项,初始化对象时无需为对象显式调用构造函数。 初始值设定项通常用在将源数据投影到新数据类型的查询表达式中。 假定一个类名为 Customer,具有公共 Name 和 Phone 属性,可以按下列代码中所示使用对象初始值设定项:
1 2 3 4
Customer cust = new Customer { Name = "Mike", Phone = "555-1212" }; var newLargeOrderCustomers = from o in IncomingOrders where o.OrderSize > 5 selectnew Customer { Name = o.Name, Phone = o.Phone };
述代码也可以使用 LINQ 的方法语法编写:
1
var newLargeOrderCustomers = IncomingOrders.Where(x => x.OrderSize > 5).Select(y => new Customer { Name = y.Name, Phone = y.Phone });
var evenNumQuery = from num in numbers where (num % 2) == 0 select num;
int evenNumCount = evenNumQuery.Count();
要强制立即执行任何查询并缓存其结果,可调用 ToList 或 ToArray 方法。
1 2 3 4 5 6 7 8 9 10 11 12
List<int> numQuery2 = (from num in numbers where (num % 2) == 0 select num).ToList();
// or like this: // numQuery3 is still an int[]
var numQuery3 = (from num in numbers where (num % 2) == 0 select num).ToArray();
基本 LINQ 查询操作
获取数据源
使用 from 子句引入数据源:
1 2 3
//queryAllCustomers is an IEnumerable<Customer> var queryAllCustomers = from cust in customers select cust;
可通过 let 子句引入其他范围变量。
1 2 3 4 5 6 7 8 9
var earlyBirdQuery = from sentence in strings let words = sentence.Split(' ') from word in words let w = word.ToLower() where w[0] == 'a' || w[0] == 'e' || w[0] == 'i' || w[0] == 'o' || w[0] == 'u' select word;
筛选
筛选器使查询仅返回表达式为 true 的元素。 将通过使用 where 子句生成结果。
1 2 3
var queryLondonCustomers = from cust in customers where cust.City == "London" select cust;
中间件排序
orderby 子句根据要排序类型的默认比较器,对返回序列中的元素排序。
1 2 3 4 5
var queryLondonCustomers3 = from cust in customers where cust.City == "London" orderby cust.Name ascending select cust;
要对结果进行从 Z 到 A 的逆序排序,请使用 orderby…descending 子句。
分组
group 子句用于对根据指定的键所获得的结果进行分组。
使用 group 子句结束查询时,结果将以列表的形式列出。 列表中的每个元素都是具有 Key 成员的对象,列表中的元素根据该键被分组。 在循环访问生成组序列的查询时,必须使用嵌套 foreach 循环。 外层循环循环访问每个组,内层循环循环访问每个组的成员。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
// queryCustomersByCity is an IEnumerable<IGrouping<string, Customer>> var queryCustomersByCity = from cust in customers group cust by cust.City;
// customerGroup is an IGrouping<string, Customer> foreach (var customerGroup in queryCustomersByCity) { Console.WriteLine(customerGroup.Key); foreach (Customer customer in customerGroup) { Console.WriteLine(" {0}", customer.Name); } }
如果必须引用某个组操作的结果,可使用 into 关键字创建能被进一步查询的标识符。 下列查询仅返回包含两个以上客户的组:
1 2 3 4 5 6 7
// custQuery is an IEnumerable<IGrouping<string, Customer>> var custQuery = from cust in customers group cust by cust.City into custGroup where custGroup.Count() > 2 orderby custGroup.Key select custGroup;
联接
在 LINQ 中,join 子句始终作用于对象集合,而非直接作用于数据库表。
1 2 3 4
var innerJoinQuery = from cust in customers join dist in distributors on cust.City equals dist.City selectnew { CustomerName = cust.Name, DistributorName = dist.Name };
classStudent { publicstring First { get; set; } publicstring Last {get; set;} publicint ID { get; set; } publicstring Street { get; set; } publicstring City { get; set; } public List<int> Scores; }
classTeacher { publicstring First { get; set; } publicstring Last { get; set; } publicint ID { get; set; } publicstring City { get; set; } } classDataTransformations { staticvoidMain() { // Create the first data source. List<Student> students = new List<Student>() { new Student { First="Svetlana", Last="Omelchenko", ID=111, Street="123 Main Street", City="Seattle", Scores= new List<int> { 97, 92, 81, 60 } }, new Student { First="Claire", Last="O’Donnell", ID=112, Street="124 Main Street", City="Redmond", Scores= new List<int> { 75, 84, 91, 39 } }, new Student { First="Sven", Last="Mortensen", ID=113, Street="125 Main Street", City="Lake City", Scores= new List<int> { 88, 94, 65, 91 } }, };
// Create the second data source. List<Teacher> teachers = new List<Teacher>() { new Teacher { First="Ann", Last="Beebe", ID=945, City="Seattle" }, new Teacher { First="Alex", Last="Robinson", ID=956, City="Redmond" }, new Teacher { First="Michiyo", Last="Sato", ID=972, City="Tacoma" } };
// Create the query. var peopleInSeattle = (from student in students where student.City == "Seattle" select student.Last) .Concat(from teacher in teachers where teacher.City == "Seattle" select teacher.Last);
Console.WriteLine("The following students and teachers live in Seattle:"); // Execute the query. foreach (var person in peopleInSeattle) { Console.WriteLine(person); }
Console.WriteLine("Press any key to exit."); Console.ReadKey(); } } /* Output: The following students and teachers live in Seattle: Omelchenko Beebe */
选择每个源元素的子集
有两种主要方法来选择源序列中每个元素的子集:
1,若要仅选择源元素的一个成员,请使用点操作。
1 2
var query = from cust in Customers select cust.City;
2,要创建包含多个源元素属性的元素,可以使用带有命名对象或匿名类型的对象初始值设定项。
1 2
var query = from cust in Customer selectnew {Name = cust.Name, City = cust.City};
将内存中对象转换为 XML
LINQ 查询可以方便地在内存中数据结构、SQL 数据库、ADO.NET 数据集和 XML 流或文档之间转换数据。
staticvoidMain() { // Create the data source by using a collection initializer. // The Student class was defined previously in this topic. List<Student> students = new List<Student>() { new Student {First="Svetlana", Last="Omelchenko", ID=111, Scores = new List<int>{97, 92, 81, 60}}, new Student {First="Claire", Last="O’Donnell", ID=112, Scores = new List<int>{75, 84, 91, 39}}, new Student {First="Sven", Last="Mortensen", ID=113, Scores = new List<int>{88, 94, 65, 91}}, };
// Create the query. var studentsToXML = new XElement("Root", from student in students let scores = string.Join(",", student.Scores) selectnewXElement("student", new XElement("First", student.First), newXElement("Last", student.Last), newXElement("Scores", scores) ) // end "student" ); // end "Root"
// Execute the query. Console.WriteLine(studentsToXML);
// Keep the console open in debug mode. Console.WriteLine("Press any key to exit."); Console.ReadKey(); }
publicvoidTest() { // Instantiate the delegates with the methods. DCovariant<Control> dControl = SampleControl; DCovariant<Button> dButton = SampleButton;
// You can assign dButton to dControl // because the DCovariant delegate is covariant. dControl = dButton;
// Invoke the delegate. dControl(); }
逆变in(泛型修饰符)
由于 lambda 表达式与其自身所分配到的委托相匹配,因此它会定义一个方法,此方法采用一个类型 Base 的参数且没有返回值。 可以将结果委托分配给类型类型 Action<Derived> 的变量,因为 T 委托的类型参数 Action<T> 是逆变类型参数。 由于 T 指定了一个参数类型,因此该代码是类型安全代码。
1 2 3
Action<Base> b = (target) => { Console.WriteLine(target.GetType().Name); }; Action<Derived> d = b; d(new Derived());
abstractclassShape { publicvirtualdouble Area { get { return0; }} }
classCircle : Shape { privatedouble r; publicCircle(double radius) { r = radius; } publicdouble Radius { get { return r; }} publicoverridedouble Area { get { return Math.PI * r * r; }} }
classShapeAreaComparer : System.Collections.Generic.IComparer<Shape> { int IComparer<Shape>.Compare(Shape a, Shape b) { if (a == null) return b == null ? 0 : -1; return b == null ? 1 : a.Area.CompareTo(b.Area); } }
classProgram { staticvoidMain() { // You can pass ShapeAreaComparer, which implements IComparer<Shape>, // even though the constructor for SortedSet<Circle> expects // IComparer<Circle>, because type parameter T of IComparer<T> is // contravariant. SortedSet<Circle> circlesByArea = new SortedSet<Circle>(new ShapeAreaComparer()) { new Circle(7.2), new Circle(100), null, new Circle(.01) };
foreach (Circle c in circlesByArea) { Console.WriteLine(c == null ? "null" : "Circle with area " + c.Area); } } }
/* This code example produces the following output: null Circle with area 0.000314159265358979 Circle with area 162.860163162095 Circle with area 31415.9265358979 */
List<string> list = new List<string>() { "test1", "test2", "test3", "test4", "test5" };
// Iterate the list by using foreach foreach (var buddy in list) { Console.WriteLine(buddy); }
// Iterate the list by using enumerator List<string>.Enumerator enumerator = list.GetEnumerator(); while (enumerator.MoveNext()) { Console.WriteLine(enumerator.Current); }
publicstatic TDelegate TypeSafeCombine<TDelegate>(this TDelegate source, TDelegate target) where TDelegate : System.Delegate => Delegate.Combine(source, target) as TDelegate;
可使用上述方法来合并相同类型的委托:
1 2 3 4 5 6 7 8 9 10
Action first = () => Console.WriteLine("this"); Action second = () => Console.WriteLine("that");
var combined = first.TypeSafeCombine(second); combined();
Func<bool> test = () => true; // Combine signature ensures combined delegates must // have the same type. //var badCombined = first.TypeSafeCombine(test);
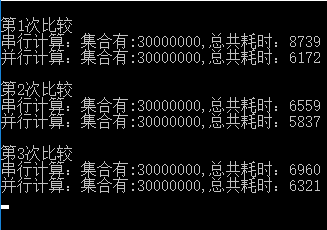
// Opt in to PLINQ with AsParallel. var evenNums = from num in source.AsParallel() where num % 2 == 0 select num; Console.WriteLine("{0} even numbers out of {1} total", evenNums.Count(), source.Count()); // The example displays the following output: // 5000 even numbers out of 10000 total
// 这里主线程会挂起等待,直到task执行完毕我们拿到返回结果 var result = task.GetAwaiter().GetResult(); // 这里不会挂起等待,因为task已经执行完了,我们可以直接拿到结果 var result2 = await task; Console.WriteLine(str); }
staticvoidMain(string[] args) { // define the function Func<string> taskBody = new Func<string>(() => { Console.WriteLine("Task body working..."); return"Task Result"; });
// create the lazy variable Lazy<Task<string>> lazyData = new Lazy<Task<string>>(() => Task<string>.Factory.StartNew(taskBody));
Console.WriteLine("Calling lazy variable"); Console.WriteLine("Result from task: {0}", lazyData.Value.Result);
// do the same thing in a single statement Lazy<Task<string>> lazyData2 = new Lazy<Task<string>>( () => Task<string>.Factory.StartNew(() => { Console.WriteLine("Task body working..."); return"Task Result"; }));
Console.WriteLine("Calling second lazy variable"); Console.WriteLine("Result from task: {0}", lazyData2.Value.Result);
// wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine(); }
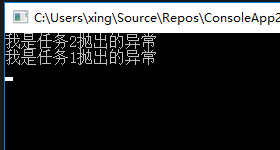
// create the tasks Task task1 = new Task(() => { ArgumentOutOfRangeException exception = new ArgumentOutOfRangeException(); exception.Source = "task1"; throw exception; }); Task task2 = new Task(() => { thrownew NullReferenceException(); }); Task task3 = new Task(() => { Console.WriteLine("Hello from Task 3"); }); // start the tasks task1.Start(); task2.Start(); task3.Start(); // wait for all of the tasks to complete // and wrap the method in a try...catch block try { Task.WaitAll(task1, task2, task3); } catch (AggregateException ex) { // enumerate the exceptions that have been aggregated foreach (Exception inner in ex.InnerExceptions) { Console.WriteLine("Exception type {0} from {1}", inner.GetType(), inner.Source); } } // wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine();
// create the cancellation token source and the token CancellationTokenSource tokenSource = new CancellationTokenSource(); CancellationToken token = tokenSource.Token; // create a task that waits on the cancellation token Task task1 = new Task(() => { // wait forever or until the token is cancelled token.WaitHandle.WaitOne(-1); // throw an exception to acknowledge the cancellation thrownew OperationCanceledException(token); }, token); // create a task that throws an exception Task task2 = new Task(() => { thrownew NullReferenceException(); }); // start the tasks task1.Start(); task2.Start(); // cancel the token tokenSource.Cancel(); // wait on the tasks and catch any exceptions try { Task.WaitAll(task1, task2); } catch (AggregateException ex) { // iterate through the inner exceptions using // the handle method ex.Handle((inner) => { if (inner is OperationCanceledException) { // ...handle task cancellation... returntrue; } else { // this is an exception we don't know how // to handle, so return false returnfalse; } }); } // wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadKey();
privatestaticvoidMain(string[] args) { // create the task Task<int> task1 = new Task<int>(() => { int sum = 0; for (int i = 0; i < 100; i++) { sum += i; } return sum; });
task1.Start(); // write out the result Console.WriteLine("Result 1: {0}", task1.Result);
// create the task Task<int> task2 = Task.Factory.StartNew<int>(() => { int sum = 0; for (int i = 0; i < 100; i++) { sum += i; } return sum; });
// write out the result Console.WriteLine("Result 1: {0}", task2.Result);
staticvoidMain(string[] args) { // create the cancellation token source CancellationTokenSource tokenSource = new CancellationTokenSource();
// create the cancellation token CancellationToken token = tokenSource.Token; // create the task
Task task = new Task(() => { for (int i = 0; i < int.MaxValue; i++) { if (token.IsCancellationRequested) { Console.WriteLine("Task cancel detected"); thrownew OperationCanceledException(token); } else { Console.WriteLine("Int value {0}", i); } } }, token);
// wait for input before we start the task Console.WriteLine("Press enter to start task"); Console.WriteLine("Press enter again to cancel task"); Console.ReadLine();
// start the task task.Start();
// read a line from the console. Console.ReadLine();
// cancel the task Console.WriteLine("Cancelling task"); tokenSource.Cancel();
// wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine(); }
// wait for input before we start the task Console.WriteLine("Press enter to start task"); Console.WriteLine("Press enter again to cancel task"); Console.ReadLine();
// start the task task.Start(); // read a line from the console. Console.ReadLine();
// cancel the task Console.WriteLine("Cancelling task"); tokenSource.Cancel();
// wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine(); }
// create the cancellation token source CancellationTokenSource tokenSource = new CancellationTokenSource();
// create the cancellation token CancellationToken token = tokenSource.Token;
// create the task Task task1 = new Task(() => { for (int i = 0; i < int.MaxValue; i++) { if (token.IsCancellationRequested) { Console.WriteLine("Task cancel detected"); thrownew OperationCanceledException(token); } else { Console.WriteLine("Int value {0}", i); } } }, token);
// create a second task that will use the wait handle Task task2 = new Task(() => { // wait on the handle token.WaitHandle.WaitOne(); // write out a message Console.WriteLine(">>>>> Wait handle released"); });
// wait for input before we start the task Console.WriteLine("Press enter to start task"); Console.WriteLine("Press enter again to cancel task"); Console.ReadLine(); // start the tasks task1.Start(); task2.Start();
// read a line from the console. Console.ReadLine();
// cancel the task Console.WriteLine("Cancelling task"); tokenSource.Cancel();
// wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine(); }
staticvoidMain(string[] args) { // create the cancellation token sources CancellationTokenSource tokenSource1 = new CancellationTokenSource(); CancellationTokenSource tokenSource2 = new CancellationTokenSource(); CancellationTokenSource tokenSource3 = new CancellationTokenSource();
// create a composite token source using multiple tokens CancellationTokenSource compositeSource = CancellationTokenSource.CreateLinkedTokenSource( tokenSource1.Token, tokenSource2.Token, tokenSource3.Token);
// create a cancellable task using the composite token Task task = new Task(() => { // wait until the token has been cancelled compositeSource.Token.WaitHandle.WaitOne(); // throw a cancellation exception thrownew OperationCanceledException(compositeSource.Token); }, compositeSource.Token);
// start the task task.Start();
// cancel one of the original tokens tokenSource2.Cancel();
// wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine(); }
staticvoidMain(string[] args) { // create the cancellation token source CancellationTokenSource tokenSource = new CancellationTokenSource();
// create the cancellation token CancellationToken token = tokenSource.Token;
// create the first task, which we will let run fully Task task1 = new Task(() => { for (int i = 0; i < Int32.MaxValue; i++) { // put the task to sleep for 10 seconds bool cancelled = token.WaitHandle.WaitOne(10000); // print out a message Console.WriteLine("Task 1 - Int value {0}. Cancelled? {1}", i, cancelled); // check to see if we have been cancelled if (cancelled) { thrownew OperationCanceledException(token); } } }, token); // start task task1.Start();
// wait for input before exiting Console.WriteLine("Press enter to cancel token."); Console.ReadLine();
// cancel the token tokenSource.Cancel();
// wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine(); }
staticvoidMain(string[] args) { // create the cancellation token source CancellationTokenSource tokenSource = new CancellationTokenSource();
// create the cancellation token CancellationToken token = tokenSource.Token;
// create the first task, which we will let run fully Task task1 = new Task(() => { for (int i = 0; i < Int32.MaxValue; i++) { // put the task to sleep for 10 seconds Thread.SpinWait(10000); // print out a message Console.WriteLine("Task 1 - Int value {0}", i); // check for task cancellation token.ThrowIfCancellationRequested(); } }, token);
// start task task1.Start();
// wait for input before exiting Console.WriteLine("Press enter to cancel token.");
Console.ReadLine(); // cancel the token tokenSource.Cancel();
// wait for input before exiting Console.WriteLine("Main method complete. Press enter to finish."); Console.ReadLine(); }
static SemaphoreSlim _sem = new SemaphoreSlim(3); // 我们限制能同时访问的线程数量是3 staticvoidMain(){ for (int i = 1; i <= 5; i++) new Thread(Enter).Start(i); Console.ReadLine(); }
// overload operator * publicstatic Fraction operator *(Fraction a, Fraction b) { returnnew Fraction(a.num * b.num, a.den * b.den); }
// user-defined conversion from Fraction to double publicstaticimplicitoperatordouble(Fraction f) { return (double)f.num / f.den; } }
classTest { staticvoidMain() { Fraction a = new Fraction(1, 2); Fraction b = new Fraction(3, 7); Fraction c = new Fraction(2, 3); Console.WriteLine((double)(a * b + c)); } } /* Output 0.880952380952381 */