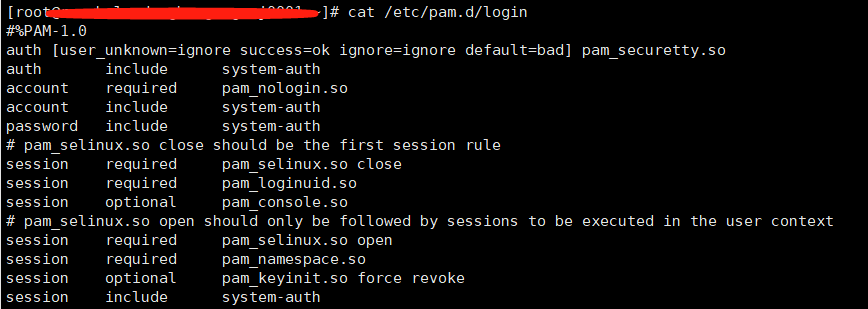
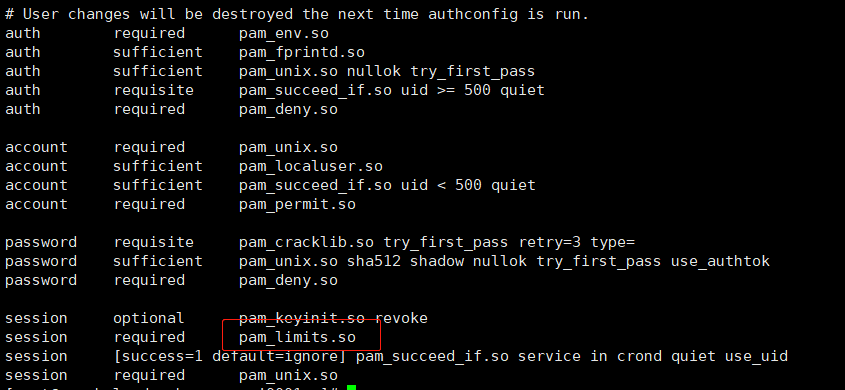
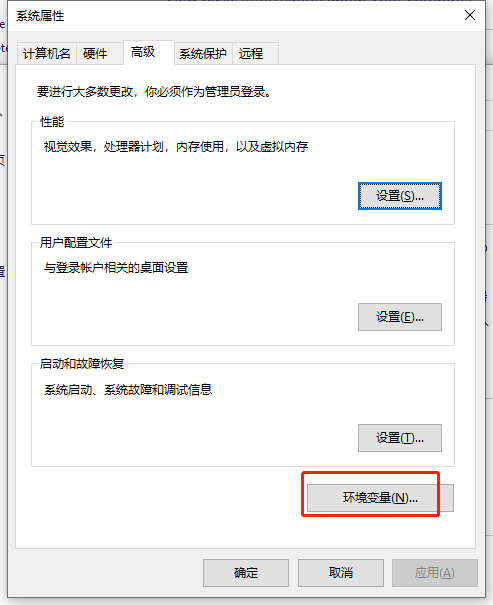
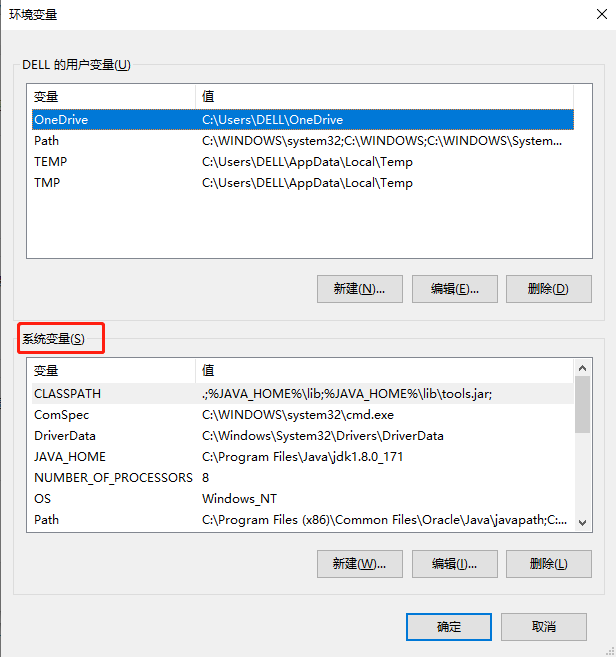
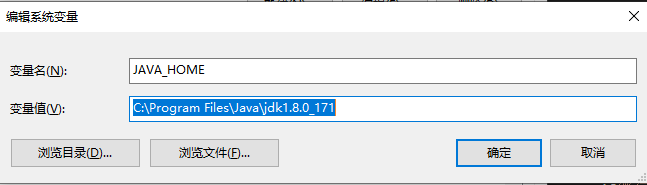
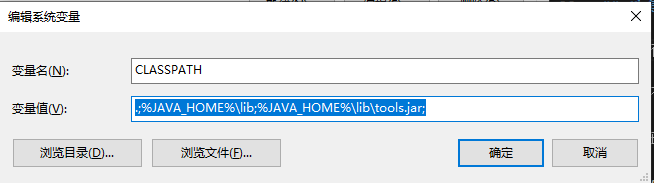
修改系统参数 修改最大可打开文件数 参考:Linux最大文件打开数
TCP监听队列大小 参考:Linux设置TCP监听队列
在 /etc/sysctl.conf 添加:
net.core.somaxconn=65000
执行命令 sysctl -p 以生效
OOM相关:vm.overcommit_memory 参考:Linux OOM机制简介
在 /etc/sysctl.conf 添加:
vm.overcommit_memory=1
执行命令 sysctl -p 以生效
Linux Transparent HugePages(透明大页) 参考:Linux Transparent HugePages(透明大页)
将 echo never > /sys/kernel/mm/transparent_hugepage/enabled 加入到文件 /etc/rc.local 中
目录结构 完成公共的 redis.conf 和一个端口号的,如 redis-6379.conf,其它端口号的配置文件基于一个修改后的端口号配置文件即可。
1 2 [root@host-192-125-30-59 redis-cluster] data log redis-6379.conf redis-6380.conf redis-6381.conf redis.conf
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 mkdir /usr/local/redis-clustercd /usr/local/redis-clustermkdir -p data log cd /usr/local/redis-cluster/datamkdir -p 6379 6380 6381cd /usr/local/redis-clustertouch redis.conftouch redis-6379.confsed 's/6379/6380/g' redis-6379.conf > /usr/local/redis-cluster/redis-6380.conf sed 's/6379/6381/g' redis-6379.conf > /usr/local/redis-cluster/redis-6381.conf /usr/local/bin/redis-server /usr/local/redis-cluster/redis-6379.conf /usr/local/bin/redis-server /usr/local/redis-cluster/redis-6380.conf /usr/local/bin/redis-server /usr/local/redis-cluster/redis-6381.conf /usr/local/bin/redis-cli -h 127.0.0.1 -p 6379 -a test /usr/local/bin/redis-cli -h 127.0.0.1 -p 6379 -a test shutdown
查看redis运行情况:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 netstat -tunpl | grep 6379 netstat -tunpl | grep 6380 netstat -tunpl | grep 6381 ps aux | grep redis [root@host-192-125-30-111 redis-cluster] tcp 0 0 0.0.0.0:16379 0.0.0.0:* LISTEN 6184/redis-server * tcp 0 0 0.0.0.0:6379 0.0.0.0:* LISTEN 6184/redis-server * tcp6 0 0 :::16379 :::* LISTEN 6184/redis-server * tcp6 0 0 :::6379 :::* LISTEN 6184/redis-server * [root@host-192-125-30-111 redis-cluster] tcp 0 0 0.0.0.0:16380 0.0.0.0:* LISTEN 6189/redis-server * tcp 0 0 0.0.0.0:6380 0.0.0.0:* LISTEN 6189/redis-server * tcp6 0 0 :::16380 :::* LISTEN 6189/redis-server * tcp6 0 0 :::6380 :::* LISTEN 6189/redis-server * [root@host-192-125-30-111 redis-cluster] tcp 0 0 0.0.0.0:16381 0.0.0.0:* LISTEN 6194/redis-server * tcp 0 0 0.0.0.0:6381 0.0.0.0:* LISTEN 6194/redis-server * tcp6 0 0 :::16381 :::* LISTEN 6194/redis-server * tcp6 0 0 :::6381 :::* LISTEN 6194/redis-server * [root@host-192-125-30-111 redis-cluster] root 6184 0.0 0.0 156964 7724 ? Ssl 10:38 0:00 /usr/local/bin/redis-server *:6379 [cluster] root 6189 0.0 0.0 153892 7692 ? Ssl 10:39 0:00 /usr/local/bin/redis-server *:6380 [cluster] root 6194 0.0 0.0 153892 7692 ? Ssl 10:39 0:00 /usr/local/bin/redis-server *:6381 [cluster] root 6339 0.0 0.0 112724 992 pts/1 S+ 10:42 0:00 grep --color=auto redis
配置redis 指定端口的配置文件 redis-PORT.conf;
公共配置 :redis.conf 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 cluster-enabled yes loglevel notice requirepass password masterauth password maxclients 1000000 timeout 0 cluster-node-timeout 15000 cluster-replica-validity-factor 0 repl-timeout 10 repl-ping-replica-period 10 replica-read-only yes replica-serve-stale-data yes replica-priority 100 aof-use-rdb-preamble yes appendonly yes appendfsync everysec daemonize yes protected-mode no tcp-backlog 511 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb no -appendfsync-on-rewrite no stop-writes-on-bgsave-error yes cluster-require-full-coverage no maxmemory 19327352832 maxmemory-policy volatile-lru client-output-buffer-limit normal 0 0 0 client-output-buffer-limit replica 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 cluster-migration-barrier 1 repl-backlog-size 1mb save 900 1 save 300 10 save 60 10000
禁止指定命令 KEYS命令很耗时,FLUSHDB和FLUSHALL命令可能导致误删除数据,所以线上环境最好禁止使用,可以在Redis配置文件增加如下配置:
1 2 3 rename-command KEYS "" rename-command FLUSHDB "" rename-command FLUSHALL ""
端口配置:redis-PORT.conf 注:PORT 需要改成具体端口;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 include /usr/local/redis-cluster/redis.conf port PORT cluster-config-file nodes-PORT.conf pidfile /var/run/redis-PORT.pid dir /usr/local/redis-cluster/data/PORTdbfilename dump-PORT.rdb appendfilename "appendonly-PORT.aof" logfile /usr/local/redis-cluster/log/redis-PORT.log
创建和启动redis集群 加上进程监控 使用 https://github.com/eyjian/libmooon/blob/master/shell/process_monitor.sh
监控示例:
1 2 3 4 REDIS_HOME=/usr/local * * * * * /usr/local/bin/process_monitor.sh "$REDIS_HOME /bin/redis-server 6379" "$REDIS_HOME /bin/redis-server $REDIS_HOME /redis-cluster/redis-6379.conf" * * * * * /usr/local/bin/process_monitor.sh "$REDIS_HOME /bin/redis-server 6380" "$REDIS_HOME /bin/redis-server $REDIS_HOME /redis-cluster/redis-6380.conf" * * * * * /usr/local/bin/process_monitor.sh "$REDIS_HOME /bin/redis-server 6381" "$REDIS_HOME /bin/redis-server $REDIS_HOME /redis-cluster/redis-6381.conf"
注意:redis的日志文件不会自动滚动,redis-server 每次在写日志时,均会以追加方式调用fopen写日志,而不处理滚动。logrotate 来滚动redis日志,命令 logrotate 一般位于目录 /usr/sbin 下。
滚动日志(可选):
1 2 3 * * * * * log =$REDIS_HOME /redis-cluster/log/redis-6379.log ;if test `ls -l $log |cut -d' ' -f5` -gt 104857600; then mv $log $log .old; fi * * * * * log =$REDIS_HOME /redis-cluster/log/redis-6380.log ;if test `ls -l $log |cut -d' ' -f5` -gt 104857600; then mv $log $log .old; fi * * * * * log =$REDIS_HOME /redis-cluster/log/redis-6381.log ;if test `ls -l $log |cut -d' ' -f5` -gt 104857600; then mv $log $log .old; fi
Redis集群TCP端口(Redis Cluster TCP ports) 每个Redis集群中的节点都需要打开两个TCP连接。一个连接用于正常的给Client提供服务,比如6379,还有一个额外的端口(通过在这个端口号上加10000)作为数据端口,比如16379。第二个端口(本例中就是16379)用于集群总线,这是一个用二进制协议的点对点通信信道。这个集群总线(Cluster bus)用于节点的失败侦测、配置更新、故障转移授权,等等。客户端从来都不应该尝试和这些集群总线端口通信,它们只应该和正常的Redis命令端口进行通信。注意,确保在你的防火墙中开放着两个端口,否则,Redis集群节点之间将无法通信。
命令端口和集群总线端口的偏移量总是10000。
注意,如果想要集群按照你想的那样工作,那么集群中的每个节点应该:
正常的客户端通信端口(通常是6379)用于和所有可到达集群的所有客户端通信
正常的客户端通信端口(通常是6379)必须对所有的客户端都开放,换言之,所有的客户端都可以访问
快速创建,启动redis集群 如果只是想快速创建和启动redis集群,而不关心过程,可使用redis官方提供的脚本 create-cluster,两步完成:
1 2 create-cluster start create-cluster create
第二步 create-cluster create 是一个交互式过程,当提示时,请输入 yes 再回车继续,第一个节点的端口号为 30001,一共会启动六个redis节点。
create-cluster位于redis源代码的 utils/create-cluster 目录下,是一个bash脚本文件。
停止集群:create-cluster stop。
创建redis cluster 1 2 /usr/local/bin/redis-cli --cluster create 192.125.30.111:6379 192.125.30.111:6380 192.125.30.59:6381 192.125.30.59:6379 192.125.30.59:6380 192.125.30.111:6381 --cluster-replicas 1
如果群集设置着密码,需要使用 -a 密码,否则会报错:(error)NOAUTH Authentication required:
1 /usr/local/bin/redis-cli -a test --cluster create 192.125.30.111:6379 192.125.30.111:6380 192.125.30.59:6381 192.125.30.59:6379 192.125.30.59:6380 192.125.30.111:6381 --cluster-replicas 1
注意:如果报以下错误,需要停止单个redis节点,并把对应的数据目录删除重建。
1 2 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. [ERR] Node 192.125.30.59:6381 is not empty. Either the node already knows other nodes (check with CLUSTER NODES) or contains some key in database 0.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 [root@host-192-125-30-111 ~] root 10547 0.0 0.0 112724 988 pts/0 R+ 11:03 0:00 grep --color=auto redis root 17367 0.1 0.0 156452 7920 ? Ssl 8月15 3:56 /usr/local/bin/redis-server *:6379 [cluster] root 17372 0.1 0.0 153892 7844 ? Ssl 8月15 3:21 /usr/local/bin/redis-server *:6380 [cluster] root 17377 0.1 0.0 153892 7848 ? Ssl 8月15 3:20 /usr/local/bin/redis-server *:6381 [cluster] [root@host-192-125-30-111 ~] [root@host-192-125-30-111 ~] [root@host-192-125-30-111 ~] [root@host-192-125-30-111 ~] [root@host-192-125-30-111 local ] bin etc games include lib lib64 libexec redis-cluster sbin share src [root@host-192-125-30-111 local ] [root@host-192-125-30-111 redis-cluster] data log redis-6379.conf redis-6380.conf redis-6381.conf redis.conf [root@host-192-125-30-111 redis-cluster] [root@host-192-125-30-111 data] 6379 6380 6381 [root@host-192-125-30-111 data] [root@host-192-125-30-111 data] [root@host-192-125-30-111 data] [root@host-192-125-30-111 data] [root@host-192-125-30-111 redis-cluster] data log redis-6379.conf redis-6380.conf redis-6381.conf redis.conf [root@host-192-125-30-111 redis-cluster] [root@host-192-125-30-111 log ] redis-6379.log redis-6380.log redis-6381.log [root@host-192-125-30-111 log ] [root@host-192-125-30-111 log ] [root@host-192-125-30-111 log ]
redis-cli 的参数说明:
1 2 3 4 5 create --cluster-replicas 1
注意:如果配置项 cluster-enabled 的值不为yes,则执行时会报错 [ERR] Node 192.168.0.251:6381 is not configured as a cluster node.
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 [root@host-192-125-30-111 redis-cluster] Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.125.30.59:6380 to 192.125.30.111:6379 Adding replica 192.125.30.111:6381 to 192.125.30.59:6381 Adding replica 192.125.30.59:6379 to 192.125.30.111:6380 M: 9df266851fa7d8d9363d584a5bc644f36ea1d052 192.125.30.111:6379 slots:[0-5460] (5461 slots) master M: 932a6ab157056e2d36e3915780b5d77138bbabdb 192.125.30.111:6380 slots:[10923-16383] (5461 slots) master M: fb9923083a70ca2131b3fb6c7633bc7275dfe33c 192.125.30.59:6381 slots:[5461-10922] (5462 slots) master S: 53ab782834f304013ac055a35e5275e5004b30c7 192.125.30.59:6379 replicates 932a6ab157056e2d36e3915780b5d77138bbabdb S: 7854f8ed0234945e89af5079331ce7779449d632 192.125.30.59:6380 replicates 9df266851fa7d8d9363d584a5bc644f36ea1d052 S: 1141e28e7b135db55cdb1c87c143ee0c0502d26d 192.125.30.111:6381 replicates fb9923083a70ca2131b3fb6c7633bc7275dfe33c Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join .. >>> Performing Cluster Check (using node 192.125.30.111:6379) M: 9df266851fa7d8d9363d584a5bc644f36ea1d052 192.125.30.111:6379 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 1141e28e7b135db55cdb1c87c143ee0c0502d26d 192.125.30.111:6381 slots: (0 slots) slave replicates fb9923083a70ca2131b3fb6c7633bc7275dfe33c M: 932a6ab157056e2d36e3915780b5d77138bbabdb 192.125.30.111:6380 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 7854f8ed0234945e89af5079331ce7779449d632 192.125.30.59:6380 slots: (0 slots) slave replicates 9df266851fa7d8d9363d584a5bc644f36ea1d052 S: 53ab782834f304013ac055a35e5275e5004b30c7 192.125.30.59:6379 slots: (0 slots) slave replicates 932a6ab157056e2d36e3915780b5d77138bbabdb M: fb9923083a70ca2131b3fb6c7633bc7275dfe33c 192.125.30.59:6381 slots:[5461-10922] (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
集群相关信息查看
1 2 3 4 5 6 7 8 9 10 11 12 13 14 /usr/local/bin/redis-cli -h 127.0.0.1 -p 6379 -a password cluster info /usr/local/bin/redis-cli -h 127.0.0.1 -p 6379 -a password cluster nodes /usr/local/bin/redis-cli -h 127.0.0.1 -p 6379 -a password info /usr/local/bin/redis-cli -h 127.0.0.1 -p 6379 -a test /usr/local/bin/redis-cli -c -h 127.0.0.1 -p 6379 -a test
ps aux|grep redis-server
查看redis进程是否已切换为集群状态(cluster)
停止redis实例,直接使用kill命令即可,如:kill 3825,重启和单机版相同。
从slaves读数据
默认不能从slaves读取数据,但建立连接后,执行一次命令 READONLY ,即可从slaves读取数据。如果想再次恢复不能从slaves读取数据,可以执行下命令 READWRITE。
群集操作 新增主(master)节点 注意一定要保证新节点里面没有添加过任何数据
以添加 192.168.0.251:6390 为例:
1 2 3 4 5 redis-cli --cluster add-node 192.168.0.251:6390 192.168.0.251:6381 redis-cli -c -p 6381 cluster nodes|grep master
新加入的master节点上没有任何数据(slots,运行redis命令cluster nodes可以看到这个情况)。当一个slave想成为master时,由于这个新的master节点不管理任何slots,它不参与选举。可以使用redis-cli的reshard为这个新master节点分配slots,如:
1 redis-cli --cluster reshard 192.168.0.251:6390
新增从(slave)节点 以添加 192.168.0.251:6390 为例:
1 redis-cli --cluster add-node 192.168.0.251:6390 192.168.0.251:6381 --cluster-slave
192.168.0.251:6390 为新添加的从节点,192.168.0.251:6381 可为集群中已有的任意节点,这种方法随机为6390指定一个master,如果想明确指定master,假设目标master的ID为3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e,则:
1 redis-cli --cluster add-node 192.168.0.251:6390 192.168.0.251:6381 --cluster-slave --cluster-master-id 3c3a0c74aae0b56170ccb03a76b60cfe7dc1912e
删除节点 从集群中删除一个节点命令格式:
1 2 redis-cli --cluster del-node 127.0.0.1:7000 `<node-id>`
如果待删除的是master节点,则在删除之前需要将该master负责的slots先全部迁到其它master。
1 2 3 4 5 6 7 $ ./redis-cli --cluster del-node 192.168.0.251:6381 082c079149a9915612d21cca8e08c831a4edeade >>> Removing node 082c079149a9915612d21cca8e08c831a4edeade from cluster 192.168.0.251:6381 >>> Sending CLUSTER FORGET messages to the cluster... >>> SHUTDOWN the node.
如果删除后,其它节点还看得到这个被删除的节点,则可通过FORGET命令解决,需要在所有还看得到的其它节点上执行:
CLUSTER FORGET <node-id>
FORGET做两件事:
从节点表剔除节点;
在60秒的时间内,阻止相同ID的节点加进来。
slots相关命令 1 2 3 4 5 CLUSTER ADDSLOTS slot1 [slot2] ... [slotN] CLUSTER DELSLOTS slot1 [slot2] ... [slotN] CLUSTER SETSLOT slot NODE node CLUSTER SETSLOT slot MIGRATING node CLUSTER SETSLOT slot IMPORTING node
参考:
Redis-5.0.0集群配置
Redis集群
分布式缓存 Redis 集群搭建
redis集群配置文件
Redis详解(二)– redis的配置文件介绍
高可用Redis(十一):使用redis-trib.rb工具搭建集群
Redis cluster tutorial
Redis Cluster Specification