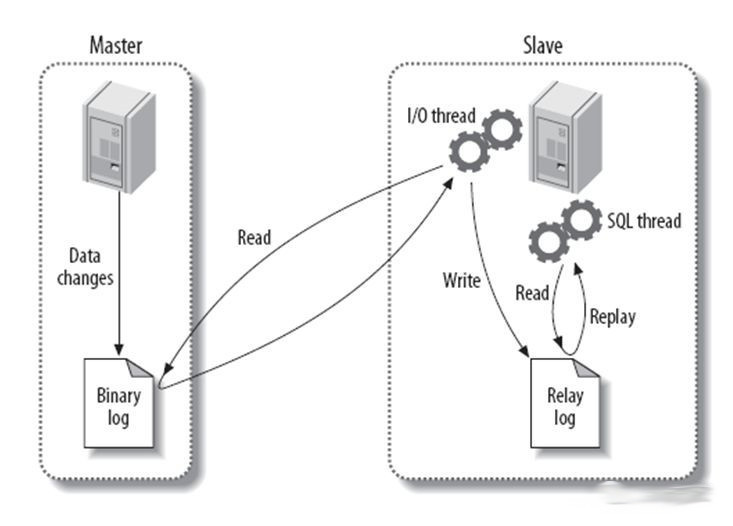
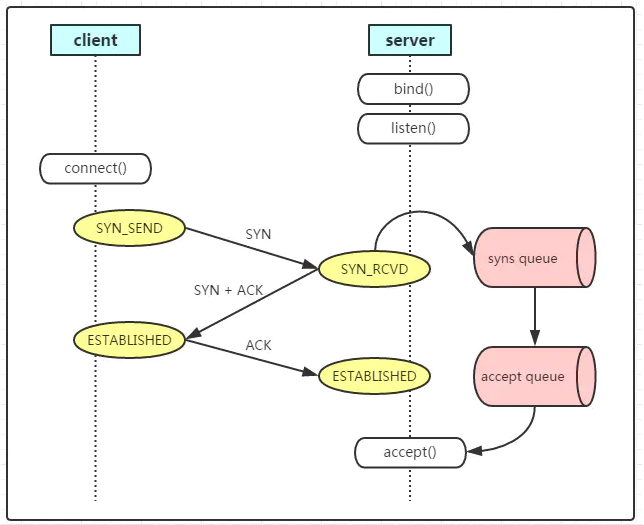
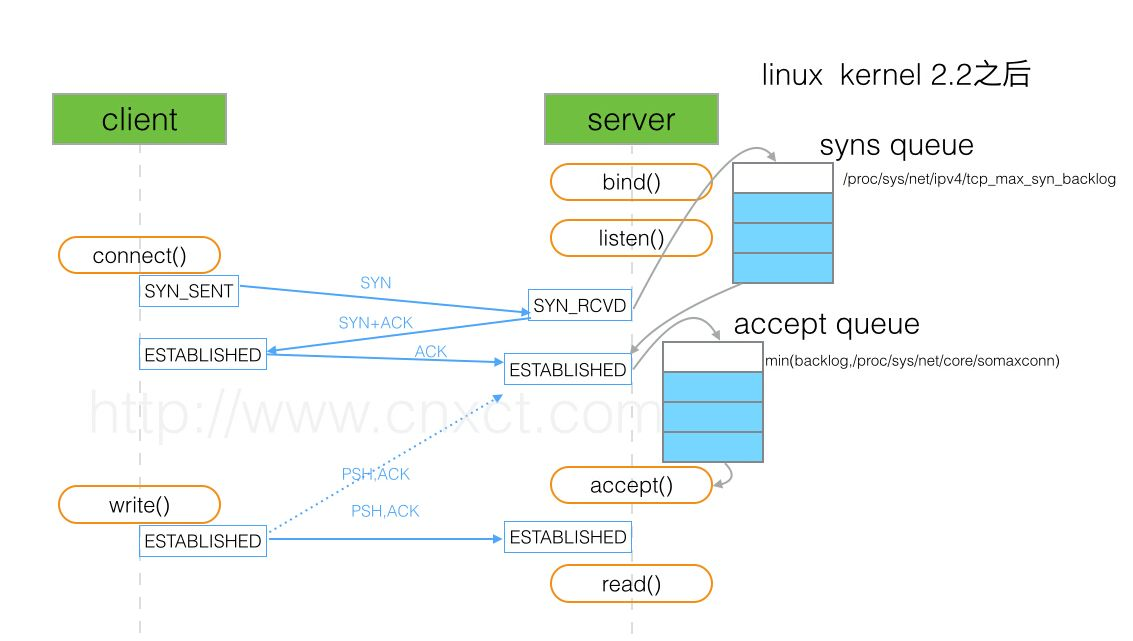
确保在主服务器上 skip_networking 选项处于 OFF 关闭状态, 这是默认值。 如果是启用的,则从站无法与主站通信,并且复制失败。
1 2 3 4 5 6 7
mysql> show variables like '%skip_networking%'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | skip_networking | OFF | +-----------------+-------+ 1 row inset (0.01 sec)
从服务器配置
1 2 3 4 5 6 7 8 9
# my.cnf 文件 [mysqld] server-id=2
#要同步的数据库 (可选) binlog-do-db=test
#要生成二进制日志文件(可选) log-bin=mysql-bin
主服务器创建用于复制数据的用户
语法:
grant 权限 on 数据库对象 to 用户
grant 权限1,权限2,…权限n on 数据库名称.表名称 to 用户名@用户地址 identified by ‘连接口令’ WITH GRANT OPTION;
示例:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
取消权限: revoke all on *.* from root@localhost;
最后执行: flush privileges;
GRANT:赋权命令
ALL PRIVILEGES:当前用户的所有权限 ON:介词 *.*:当前用户对所有数据库和表的相应操作权限 TO:介词 ‘root’@’%’:权限赋给root用户,所有ip都能连接 IDENTIFIED BY ‘123456’:连接时输入密码,密码为123456 WITH GRANT OPTION:允许级联赋权,表示该用户可以将自己拥有的权限授权给别人。
# 创建用户 create user 'slave'@'%' identified by '123456'; # 或 CREATE USER 'slave'@'%'
# 设置用户权限 # 授予复制账号 REPLICATION CLIENT 权限,复制用户可以使用 # SHOW MASTER STATUS, SHOW SLAVE STATUS 和 SHOW BINARY LOGS来确定复制状态。 # 授予复制账号 REPLICATION SLAVE 权限,复制才能真正地工作。 grant replication slave,replication client on *.* to 'slave'@'%'; # 或 GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%' identified by '123456';
mysql>show processlist\G ***************************1.row*************************** Id: 69 User: slave Host: 192.123.75.69:55453 db: NULL Command: Binlog Dump Time: 63184 State: Master has sent all binlog to slave; waiting for more updates Info: NULL
该线程是 Binlog Dump 为连接的从属服务的复制线程。该 State 信息表明所有未完成的更新已发送到从站,并且主站正在等待更多更新发生。如果 Binlog Dump 在主服务器上看不到任何 线程,则表示复制未运行,说明目前没有连接任何从站。
EnvironmentFile=/usr/local/minio/minio.conf ExecStartPre=/bin/bash -c "if [ -z \"${MINIO_VOLUMES}\" ]; then echo \"Variable MINIO_VOLUMES not set in /etc/default/minio\"; exit 1; fi"
ExecStart=/usr/local/minio/bin/minio server $MINIO_OPTS$MINIO_VOLUMES
# Let systemd restart this service always Restart=always
# Specifies the maximum file descriptor number that can be opened by this process LimitNOFILE=65536
# Disable timeout logic and wait until process is stopped TimeoutStopSec=infinity SendSIGKILL=no
[Install] WantedBy=multi-user.target
# Built for ${project.name}-${project.version} (${project.name})
Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
Expression #1 of ORDER BY clause is not in SELECT list, references column 'sort' which is not in SELECT list; this is incompatible with DISTINCT
说明
mysql 5.7版本默认的sql配置是:sql_mode=”ONLY_FULL_GROUP_BY”,这个配置严格执行了”SQL92标准”。
原因分析: 再输出的结果 target list 中,即select后面跟着的字段,还有一个地方 group by column,就是 group by后面跟着的字段。由于开启了 ONLY_FULL_GROUP_BY 的设置,所以如果一个字段没有在 target list 和 group by 字段中同时出现,或者是聚合函数的值的话,那么这条sql查询是被mysql认为非法的,会报错误。
解决方法
暂时修改sql_mode
重启mysql数据库服务之后,ONLY_FULL_GROUP_BY还会出现。
1
set @@GLOBAL.sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
修改mysql配置文件
修改 mysql 配置文件,/usr/local/mysql/my.cnf,添加如下代码,之后重启mysql服务。
如果服务器否定了”预检”请求,会返回一个正常的HTTP回应,但是没有任何 CORS 相关的头信息字段。这时,浏览器就会认定,服务器不同意预检请求,因此触发一个错误,被 XMLHttpRequest 对象的 onerror 回调函数捕获。控制台会打印出如下的报错信息。
1 2
XMLHttpRequest cannot load http://api.alice.com. Originhttp://api.bob.com is not allowed by Access-Control-Allow-Origin.
服务器回应的其他 CORS 相关字段如下。
1 2 3 4
Access-Control-Allow-Methods: GET, POST, PUT Access-Control-Allow-Headers: X-Custom-Header Access-Control-Allow-Credentials: true Access-Control-Max-Age: 1728000
Linux下的大页分为两种类型:标准大页(Huge Pages)和透明大页(Transparent Huge Pages)。Huge Pages有时候也翻译成大页/标准大页/传统大页,它们都是Huge Pages的不同中文翻译名而已。目的是使用更大的内存页面(memory page size) 以适应越来越大的系统内存,让操作系统可以支持现代硬件架构的大页面容量功能。透明大页(Transparent Huge Pages)缩写为THP,这个是RHEL 6(其它分支版本SUSE Linux Enterprise Server 11, and Oracle Linux 6 with earlier releases of Oracle Linux Unbreakable Enterprise Kernel 2 (UEK2))开始引入的一个功能。具体可以参考官方文档。这两者的区别在于大页的分配机制,标准大页管理是预分配的方式,而透明大页管理则是动态分配的方式。
iftest -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never > /sys/kernel/mm/transparent_hugepage/enabled fi iftest -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never > /sys/kernel/mm/transparent_hugepage/defrag fi
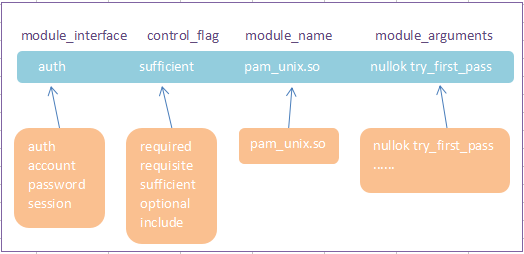
[root@host-192-125-30-59 ~]# vim /etc/pam.d/system-auth-ac #%PAM-1.0 # This file is auto-generated. # User changes will be destroyed the next time authconfig is run. auth required pam_env.so auth required pam_faildelay.so delay=2000000 auth sufficient pam_unix.so nullok try_first_pass auth requisite pam_succeed_if.so uid >= 1000 quiet_success auth required pam_deny.so