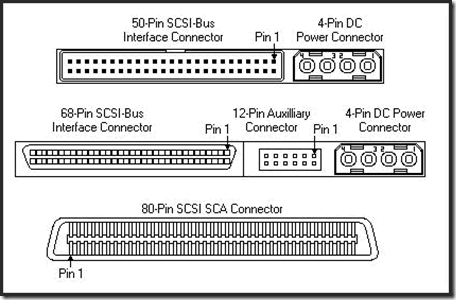
硬盘接口的分类
硬盘接口通常分为五种类型:IDE接口、SATA接口、SCSI接口、SAS接口、光纤通道(FC)。
硬盘的分类
硬盘分为固态硬盘(SSD 盘)、机械硬盘(HDD)、混合硬盘(HHD)三种。
SSD采用闪存颗粒来存储,HDD采用磁性碟片来存储,混合硬盘(HHD: Hybrid Hard Disk)是把磁性硬盘和闪存集成到一起的一种硬盘。绝大多数硬盘都是固定硬盘,被永久性地密封固定在硬盘驱动器中。
IDE是俗称的并口,SATA是俗称的串口,这两种硬盘是个人电脑和低端服务器常见的硬盘。
SCSI是 小型计算机系统专用接口 的简称,SCSI硬盘就是采用这种接口的硬盘。SAS就是串口的SCSI接口。一般服务器硬盘采用这两类接口,其性能比上述两种硬盘要高,稳定性更强,但是价格高,容量小,噪音大。
FC是光纤通道,和SCIS接口一样,光纤通道最初也不是为硬盘设计开发的接口技术,是专门为网络系统设计的,但随着存储系统对速度的需求,才逐渐应用到硬盘系统中。
SSD也称作电子硬盘或者固态电子盘,是由控制单元和固态存储单元(DRAM或FLASH芯片)组成的硬盘。
固态硬盘的接口规范和定义、功能及使用方法上与普通硬盘的相同,在产品外形和尺寸上也与普通硬盘一致。新一代的固态硬盘普遍采用SATA-2接口,但其成本较高。
IDE/ATA
IDE( Integrated Drive Electronics 集成驱动器电子)的缩写,它的本意是指把控制器与盘体集成在一起的硬盘驱动器,是一种硬盘的传输接口,它有另一个名称叫做 ATA(Advanced Technology Attachment),这两个名词都有厂商在用,指的是相同的东西。
ATA(Advanced Technology Attachment)高技术配置,一般来说,ATA是一种控制器技术,而 IDE(Integrated Drive Electronics) 是一个匹配它的磁盘驱动器技术,ATA和IDE通常可以互换使用。ATA下一步的技术是SATA(Serial ATA),串行ATA。有了SATA之后,原来的 ATA又被称为 PATA(Parallel ATA),并行ATA。一般意义上,IDE 和 PATA 是说的同一种东西,它们的进化型是SATA。
IDE的规格后来有所进步,而推出了 EIDE(Enhanced IDE) 的规格名称,而这个规格同时又被称为 Fast ATA。所不同的是 Fast ATA 是专指硬盘接口,而 EIDE 还制定了连接光盘等非硬盘产品的标准。而这个连接非硬盘类的IDE标准,又称为ATAPI接口。而之后再推出更快的接口,名称都只剩下ATA的字样,像是 Ultra ATA、ATA/66、ATA/100 等。
早期的IDE接口有两种传输模式,一个是 PIO(Programming I/O)模式,另一个是 DMA(Direct Memory Access)。虽然DMA模式系统资源占用少,但需要额外的驱动程序或设置,因此被接受的程度比较低。后来在对速度要求愈来愈高的情况下,DMA模式由于执行效率较好,操作系统开始直接支持,而且厂商更推出了愈来愈快的DMA模式传输速度标准。而从英特尔的430TX芯片组开始,就提供了对Ultra DMA 33的支持,提供了最大33MB/sec的的数据传输率,以后又很快发展到了ATA 66,ATA 100以及迈拓提出的ATA 133标准,分别提供66MB/sec,100MB/sec以及133MB/sec的最大数据传输率。
值得注意的是,迈拓提出的ATA 133标准并没能获得业界的广泛支持,硬盘厂商中只有迈拓自己才采用ATA 133标准,而日立(IBM),希捷和西部数据则都采用 ATA 100 标准,芯片组厂商中也只有 VIA,SIS,ALi 以及 nViidia 对次标准提供支持,芯片组厂商中英特尔则只支持 ATA 100 标准。
各种IDE标准都能很好的向下兼容,例如 ATA 133 兼容 ATA 66/100 和 Ultra DMA33 ,而 ATA 100 也兼容 Ultra DMA 33/66 。
要特别注意的是,对 ATA 66 以及以上的IDE接口传输标准而言,必须使用专门的80芯IDE排线,其与普通的40芯IDE排线相比,增加了40条地线以提高信号的稳定性。

特点:
一般使用16-bit数据总线, 每次总线处理时传送2个字节。PATA接口一般是100Mbytes/sec带宽,数据总线必须锁定在50MHz,为了减小滤波设计的复杂性,PATA使用Ultra总线,通过“双倍数据比率”或者2个边缘(上升沿和下降沿)时钟机制用来进行DMA传输。这样在数据滤波的上升沿和下降沿都采集数据,就降低一半所需要的滤波频率。这样带宽就是:25MHz 时钟频率x 2 双倍时钟频率x 16 位/每一个边缘/ 8 位/每个字节= 100 Mbytes/sec。
优点:
自问世以来,一直以其价廉、稳定性好、标准化程度高等特点,深得广大中低端用户的青睐,甚至在某些高端应用领域,如服务器应用中也有一定的市场。
缺点:
随着CPU时钟频率和内存带宽的不断提升,其接口协议PATA(Paralle ATA)逐渐显现出不足来。一方面,硬盘制造技术的成熟使ATA硬盘的单位价格逐渐降低,另一方面,由于采用并行总线接口,传输数据和信号的总线是复用的,因此传输速率会受到一定的限制。如果要提高传输的速率,那么传输的数据和信号往往会产生干扰,从而导致错误。
在当今的许多大型企业中,PATA现有的传输速率已经逐渐不能满足用户的需求。
SATA
使用 SATA(Serial ATA)口的硬盘又叫 串口硬盘。2001年,由Intel、APT、Dell、IBM、希捷、迈拓这几大厂商组成的Serial ATA委员会正式确立了Serial ATA 1.0规范。
SATA以它串行的数据发送方式得名。在数据传输的过程中,数据线和信号线独立使用,并且传输的时钟频率保持独立,因此同以往的PATA相比,SATA的传输速率可以达到并行的30倍。可以说:SATA技术并不是简单意义上的PATA技术的改进,而是一种全新的总线架构。

2002年,虽然串行ATA的相关设备还未正式上市,但Serial ATA委员会已抢先确立了Serial ATA 2.0规范(SATA II)。
Serial ATA采用串行连接方式,串行ATA总线使用嵌入式时钟信号,具备了更强的纠错能力,与以往相比其最大的区别在于能对传输指令(不仅仅是数据)进行检查,如果发现错误会自动矫正,这在很大程度上提高了数据传输的可靠性。串行接口还具有结构简单、支持热插拔的优点。
串口硬盘是一种完全不同于并行ATA的新型硬盘接口类型,由于采用串行方式传输数据而知名。相对于并行ATA来说,就具有非常多的优势。
- 1,Serial ATA以连续串行的方式传送数据,一次只会传送1位数据。这样能减少SATA接口的针脚数目,使连接电缆数目变少,效率也会更高。
- 2,实际上,Serial ATA 仅用四支针脚就能完成所有的工作,分别用于连接电缆、连接地线、发送数据和接收数据,同时这样的架构还能降低系统能耗和减小系统复杂性。
- Serial ATA的起点更高、发展潜力更大,Serial ATA 1.0定义的数据传输率可达150MB/s;这比最快的并行ATA(即ATA/133)所能达到133MB/s的最高数据传输率还高;而在Serial ATA 2.0的数据传输率达到300MB/s;最终SATA将实现600MB/s的最高数据传输率。
在选购主板时,其实并无必要太在意IDE接口传输标准有多快,其实在ATA 100,ATA 133以及SATA 150下硬盘性能都差不多,因为受限于硬盘的机械结构和数据存取方式,硬盘的性能瓶颈是硬盘的内部数据传输率而非外部接口标准,目前主流硬盘的内部数据传输率离ATA 100的100MB/sec都还差得很远。
SATA II
SATA的速度是每秒1.5Gbps(150MB/sec),SATA2(Serial ATA 2.0规范)的速度是每秒3Gbps(300MB/sec)。SATA II接口主板能插SATA硬盘,SATA接口主板不能插 SATA II 盘硬,这都是向下兼容的。
SATA II是在SATA的基础上发展起来的,其主要特征是外部传输率从SATA的1.5G进一步提高到了3G,此外还包括NCQ(Native Command Queuing,原生命令队列)、端口多路器(Port Multiplier)、交错启动(Staggered Spin-up)等一系列的技术特征。单纯的外部传输率达到3Gbps并不是真正的SATA II。
SATA II的关键技术就是3Gbps的外部传输率和NCQ技术。 NCQ技术可以对硬盘的指令执行顺序进行优化,避免像传统硬盘那样机械地按照接收指令的先后顺序移动磁头读写硬盘的不同位置,与此相反,它会在接收命令后对其进行排序,排序后的磁头将以高效率的顺序进行寻址,从而避免磁头反复移动带来的损耗,延长硬盘寿命。
另外并非所有的SATA硬盘都可以使用NCQ技术,除了硬盘本身要支持 NCQ之外,也要求主板芯片组的SATA控制器支持NCQ。此外,NCQ技术不支持FAT文件系统,只支持NTFS文件系统。
由于SATA设备市场比较混乱,不少SATA设备提供商在市场宣传中滥用 SATA II 的现象愈演愈烈,例如某些号称 SATA II 的硬盘却仅支持3Gbps而不支持NCQ,而某些只具有1.5Gbps的硬盘却又支持NCQ。所以,由希捷(Seagate)所主导的 SATA-IO ( Serial ATA International Organization,SATA国际组织,原SATA工作组)又宣布了SATA 2.5规范,收录了原先SATA II所具有的大部分功能——从3Gbps和NCQ到交错启动(Staggered Spin-up)、热插拔(Hot Plug)、端口多路器(Port Multiplier)以及比较新的eSATA(External SATA,外置式SATA接口)等等。
值得注意的是,部分采用较早的仅支持1.5Gbps的南桥芯片(例如VIA VT8237和NVIDIA nForce2 MCP-R/MCP-Gb)的主板在使用SATA II硬盘时,可能会出现找不到硬盘或蓝屏的情况。不过大部分硬盘厂商都在硬盘上设置了一个速度选择跳线,以便强制选择1.5Gbps或3Gbps的工作模式(少数硬盘厂商则是通过相应的工具软件来设置),只要把硬盘强制设置为1.5Gbps,SATA II硬盘照样可以在老主板上正常使用。
SATA硬盘在设置RAID模式时,一般都需要安装主板芯片组厂商所提供的驱动,但也有少数较老的SATA RAID控制器在打了最新补丁的某些版本的Windows XP系统里不需要加载驱动就可以组建RAID。
SCSI
SCSI的英文全称为 Small Computer System Interface(小型计算机系统接口),是同IDE(ATA)完全不同的接口,IDE接口是普通PC的标准接口,而SCSI并不是专门为硬盘设计的接口,是一种广泛应用于小型机上的高速数据传输技术。SCSI接口具有应用范围广、多任务、带宽大、CPU占用率低,以及热插拔等优点,但较高的价格使得它很难如IDE硬盘般普及,因此SCSI硬盘主要应用于中、高端服务器和高档工作站中。

优点:
系统占用率极低,转速快,传输率高.
缺点:
价格高、安装不便、还需要设置及其安装驱动程序,因此这种接口的硬盘大多用于服务器等高端应用场合。
SAS
SAS(Serial Attached SCSI)即串行连接SCSI,是新一代的SCSI技术。和现在流行的Serial ATA(SATA)硬盘相同,都是采用串行技术以获得更高的传输速度,并通过缩短连结线改善内部空间等。SAS是并行SCSI接口之后开发出的全新接口。此接口的设计是为了改善存储系统的效能、可用性和扩充性,并且提供与SATA硬盘的兼容性。
SAS的接口技术可以向下兼容SATA。具体来说,二者的兼容性主要体现在物理层和协议层的兼容。
1,在物理层,SAS接口和SATA接口完全兼容,SATA硬盘可以直接使用在SAS的环境中,从接口标准上而言,SATA是SAS的一个子标准,因此SAS控制器可以直接操控SATA硬盘,但是SAS却不能直接使用在SATA的环境中,因为SATA控制器并不能对SAS硬盘进行控制;
2,在协议层,SAS由3种类型协议组成,根据连接的不同设备使用相应的协议进行数据传输。其中串行SCSI协议(SSP)用于传输SCSI命令;SCSI管理协议(SMP)用于对连接设备的维护和管理;SATA通道协议(STP)用于SAS和SATA之间数据的传输。因此在这3种协议的配合下,SAS可以和SATA以及部分SCSI设备无缝结合。
SAS系统的背板(Backplane)既可以连接具有双端口、高性能的SAS驱动器,也可以连接高容量、低成本的SATA驱动器。所以SAS驱动器和SATA驱动器可以同时存在于一个存储系统之中。但需要注意的是,SATA系统并不兼容SAS,所以SAS驱动器不能连接到SATA背板上。由于SAS系统的兼容性,使用户能够运用不同接口的硬盘来满足各类应用在容量上或效能上的需求,因此在扩充存储系统时拥有更多的弹性,让存储设备发挥最大的投资效益。
在系统中,每一个SAS端口可以最多可以连接16256个外部设备,并且SAS采取直接的点到点的串行传输方式,传输的速率高达3Gbps,估计以后会有6Gbps乃至12Gbps的高速接口出现。
SAS的接口也做了较大的改进,它同时提供了3.5英寸和2.5英寸的接口,因此能够适合不同服务器环境的需求。
SAS依靠SAS扩展器来连接更多的设备,目前的扩展器以12端口居多,不过根据板卡厂商产品研发计划显示,未来会有28、36端口的扩展器引入,来连接SAS设备、主机设备或者其他的SAS扩展器。
和传统并行SCSI接口比较起来,SAS不仅在接口速度上得到显著提升(现在主流Ultra 320 SCSI速度为320MB/sec,而SAS才刚起步速度就达到300MB/sec,未来会达到600MB/sec甚至更多),而且由于采用了串行线缆,不仅可以实现更长的连接距离,还能够提高抗干扰能力,并且这种细细的线缆还可以显著改善机箱内部的散热情况。
SAS目前的不足主要有以下方面:
只有希捷、迈拓以及富士通等为数不多的硬盘厂商推出了SAS接口硬盘,品种太少,其他厂商的SAS硬盘多数处在产品内部测试阶段。此外周边的SAS控制器芯片或者一些SAS转接卡的种类更是不多,多数集中在LSI以及Adaptec公司手中。
比起同容量的Ultra 320 SCSI硬盘,SAS硬盘要贵了一倍还多。一直居高不下的价格直接影响了用户的采购数量和渠道的消化数量,而无法形成大批量生产的SAS 硬盘,其成本的压力又会反过来促使价格无法下降。
如果用户想要做个简单的RAID级别,那么不仅需要购买多块SAS硬盘,还要购买昂贵的RAID卡,价格基本上和硬盘相当。
SAS硬盘的接口速度并不代表数据传输速度,受到硬盘机械结构限制,现在SAS硬盘的机械结构和SCSI硬盘几乎一样。目前数据传输的瓶颈集中在由硬盘内部机械机构、硬盘存储技术、磁盘转速,所决定的硬盘内部数据传输速度,也就是80MBsec左右,SAS硬盘的性能提升不明显。
从现在已经推出的产品来看,SAS硬盘更多的被应用在高端4路服务器上,而4路以上服务器用户并非一味追求高速度的硬盘接口技术,最吸引他们的应该是成熟、稳定的硬件产品,虽然SAS接口服务器和SCSI接口产品在速度、稳定性上差不多,但目前的技术和产品都还不够成熟。
不过随着英特尔等主板芯片组制造商、希捷等硬盘制造商以及众多的服务器制造商的大力推动,SAS的相关产品技术会逐步成熟,价格也会逐步滑落,早晚都会成为服务器硬盘的主流接口。
FC
光纤通道的英文拼写是Fiber Channel,和SCIS接口一样光纤通道最初也不是为硬盘设计开发的接口技术,是专门为网络系统设计的,但随着存储系统对速度的需求,才逐渐应用到硬盘系统中。光纤通道硬盘是为提高多硬盘存储系统的速度和灵活性才开发的,它的出现大大提高了多硬盘系统的通信速度。光纤通道的主要特性有:热插拔性、高速带宽、远程连接、连接设备数量大等。
FC硬盘是指采用FC-AL( Fiber Channel Arbitrated Loop,光纤通道仲裁环) 接口模式的磁盘。FC-AL使光纤通道能够直接作为硬盘连接接口,为高吞吐量性能密集型系统的设计者开辟了一条提高I/O性能水平的途径。目前高端存储产品使用的都是FC接口的硬盘。
FC硬盘名称由于通过光学物理通道进行工作,因此起名为光纤硬盘,现在也支持铜线物理通道。就像是IEEE-1394, Fibre Channel 实际上定义为SCSI-3标准一类,属于SCSI的同胞兄弟。作为串行接口FC-AL峰值可以达到2Gbits/s甚至是4Gbits/s。而且通过光学连接设备最大传输距离可以达到10KM。通过FC-loop可以连接127个设备,也就是为什么基于FC硬盘的存储设备通常可以连接几百颗甚至千颗硬盘提供大容量存储空间。
关于光纤硬盘以其的优越的性能、稳定的传输,在企业存储高端应用中担当重要角色。业界普遍关注的焦点在于光纤接口的带宽。最早普及使用的光纤接口带宽为1Gb,随后2Gb带宽光纤产品统治市场已经长达三年时间。现在的带宽标准是4Gb,目前普遍厂商都已经采用4Gb相关产品。8Gb光纤产品也将在不久的将来取代4Gb光纤成为市场主流。
4Gb是以2Gb为基础延伸的传输协议,可以向下兼容1Gb和2Gb,所使用的光纤线材、连接端口也都相同,意味着使用者在导入4Gb设备时,不需为了兼容性问题更换旧有的设备,不但可以保护既有的投资,也可以采取渐进式升级的方式,逐步淘汰旧有的2Gb设备。
光纤通道是为在像服务器这样的多硬盘系统环境而设计,能满足高端工作站、服务器、海量存储子网络、外设间通过集线器、交换机和点对点连接进行双向、串行数据通讯等系统对高数据传输率的要求。
SSD
固态硬盘(Solid State Disk或Solid State Drive),也称作电子硬盘或者固态电子盘,是由控制单元和固态存储单元(DRAM或FLASH芯片)组成的硬盘。存储单元负责存储数据,控制单元负责读取、写入数据。拥有速度快,耐用防震,无噪音,重量轻等优点。固态硬盘的接口规范和定义、功能及使用方法上与普通硬盘的相同,在产品外形和尺寸上也与普通硬盘一致。由于固态硬盘没有普通硬盘的旋转介质,因而抗震性极佳。其芯片的工作温度范围很宽(-40~85℃)。目前广泛应用于军事、车载、工控、视频监控、网络监控、网络终端、电力、医疗、航空等、导航设备等领域。目前由于成本较高,正在逐渐普及到DIY市场。
由于固态硬盘技术与传统硬盘技术不同,所以产生了不少新兴的存储器厂商。厂商只需购买NAND存储器,再配合适当的控制芯片,就可以制造固态硬盘了。新一代的固态硬盘普遍采用SATA-2接口。
固态硬盘的存储介质分为两种,一种是采用闪存(FLASH芯片)作为存储介质,另外一种是采用DRAM作为存储介质。
SSD固态优点:
- 第一,SSD不需要机械结构,完全的半导体化,不存在数据查找时间、延迟时间和磁盘寻道时间,数据存取速度快,读取数据的能力在230M/s以上,最高的可达500M/s以上。
- 第二,SSD全部采用闪存芯片,经久耐用,防震抗摔,即使发生与硬物碰撞,数据丢失的可能性也能够降到最小。
- 第三,得益于无机械部件及FLASH闪存芯片,SSD没有任何噪音,功耗低。
- 第四,质量轻,比常规1.8英寸硬盘重量轻20-30克,使得便携设备搭载多块SSD成为可能。同时因其完全半导体化,无结构限制,可根据实际情况设计成各种不同接口、形状的特殊电子硬盘。
SSD的劣势
固态硬盘成本高。
固态硬盘的寿命有限 对于采用Nand Flash作为存储介质的SSD来说,怀疑其使用寿命也不是没有道理的,理论上MLC的写入寿命为1万次,SLC的写入寿命为10万次。但是否意味着一个 固态硬盘的寿命只有2到3年呢,这个也不一定。英特尔表示保证能在未来5年里,每天可以向其MLC SSD产品中写入100GB的数据,并且保证其数据的完整性。如果不是写入太频繁的话,正常使用用5年以上是没有问题的。
(1)基于闪存的固态硬盘(IDE FLASH DISK、Serial ATA Flash Disk)
采用FLASH芯片作为存储介质,这也是我们通常所说的SSD。它的外观可以被制作成多种模样,例如:笔记本硬盘、微硬盘、存储卡、优盘等样式。这种SSD固态硬盘最大的优点就是可以移动,而且数据保护不受电源控制,能适应于各种环境,但是使用年限不高,适合于个人用户使用。
在基于闪存的固态硬盘中,存储单元又分为两类:SLC(Single Layer Cell 单层单元)和MLC(Multi-Level Cell多层单元)。
SLC的特点是成本高、容量小、但是速度快,而MLC的特点是容量大成本低,但是速度慢。MLC的每个单元是2bit的,相对SLC来说整整多了一倍。不过,由于每个MLC存储单元中存放的资料较多,结构相对复杂,出错的几率会增加,必须进行错误修正,这个动作导致其性能大幅落后于结构简单的SLC闪存。此外,SLC闪存的优点是复写次数高达100000次,比MLC闪存高10倍。此外,为了保证MLC的寿命,控制芯片都校验和智能磨损平衡技术算法,使得每个存储单元的写入次数可以平均分摊,达到100万小时故障间隔时间(MTBF)。
采用DRAM作为存储介质,目前应用范围较窄。它仿效传统硬盘的设计、可被绝大部分操作系统的文件系统工具进行卷设置和管理,并提供工业标准的PCI和FC接口用于连接主机或者服务器。应用方式可分为SSD硬盘和SSD硬盘阵列两种。它是一种高性能的存储器,而且使用寿命很长,美中不足的是需要独立电源来保护数据安全。
单纯硬盘的硬盘接口协议也不是衡量一个存储系统性能指标的唯一要素,除了硬盘性能指标以外,存储系统的硬件设计,前端主机接口等性能指标也同样对存储系统的整体性能影响巨大。
如果需要应用于I/O负载较轻的应用比如文件共享、FTP、音频存储、数据备份等可以考虑基于SATA硬盘的阵列。如果I/O负载较重的FTP、VOD、EMAIL、Web、数据库应用,那么可以考虑基于SAS/FC硬盘的存储系统。
总结
单纯硬盘的硬盘接口协议也不是衡量一个存储系统性能指标的唯一要素,除了硬盘性能指标以外,存储系统的硬件设计,前端主机接口等性能指标也同样对存储系统的整体性能影响巨大。
如果需要应用于I/O负载较轻的应用比如文件共享、FTP、音频存储、数据备份等可以考虑基于 SATA 硬盘的阵列。
如果I/O负载较重的FTP、VOD、EMAIL、Web、数据库应用,那么可以考虑基于 SAS/FC 硬盘的存储系统。
参考:
硬盘基础知识(HDD、SSD、IDE、PATA、SATA、SCSI、SAS)
IDE、SATA、SCSI、SAS、FC、SSD硬盘类型介绍
识别 Linux上的设备(磁盘)类型
ovirt磁盘类型(IDE, virtio, virtio-scsi)