强制类型转换是把变量从一种类型转换为另一种数据类型。
实例:
使用强制类型转换运算符把一个整数变量除以另一个整数变量,得到一个浮点数:
1 |
|
强制类型转换是把变量从一种类型转换为另一种数据类型。
实例:
使用强制类型转换运算符把一个整数变量除以另一个整数变量,得到一个浮点数:
1 |
|
头文件是扩展名为 .h 的文件,包含了 C 函数声明和宏定义,被多个源文件中引用共享。
有两种类型的头文件:程序员编写的头文件和编译器自带的头文件。
在程序中要使用头文件,需要使用 C 预处理指令 #include 来引用它。前面我们已经看过 stdio.h 头文件,它是编译器自带的头文件。
A simple practice in C 或 C++ 程序中,建议把所有的常量、宏、系统全局变量和函数原型写在头文件中,在需要的时候随时引用这些头文件。
C 预处理器不是编译器的组成部分,但是它是编译过程中一个单独的步骤。简言之,C 预处理器只不过是一个文本替换工具而已,它们会指示编译器在实际编译之前完成所需的预处理。我们将把 C 预处理器(C Preprocessor)简写为 CPP。
所有的预处理器命令都是以 # 开头。它必须是第一个非空字符,为了增强可读性,预处理器指令应从第一列开始。
下面列出了所有重要的预处理器指令:
| 指令 | 描述 |
|---|---|
| #define | 定义宏 |
| #include | 包含一个源代码文件 |
| #undef | 取消已定义的宏 |
| #ifdef | 如果宏已经定义,则返回真 |
| #ifndef | 如果宏没有定义,则返回真 |
| #if | 如果给定条件为真,则编译下面代码 |
| #else | #if 的替代方案 |
| #elif | 如果前面的 #if 给定条件不为真,当前条件为真,则编译下面代码 |
| #endif | 结束一个 #if……#else 条件编译块 |
| #error | 当遇到标准错误时,输出错误消息 |
| #pragma | 使用标准化方法,向编译器发布特殊的命令到编译器中 |
可以使用 fopen() 函数来创建一个新的文件或者打开一个已有的文件。
1 | FILE *fopen( const char * filename, const char * mode ); |
filename 是字符串,用来命名文件;访问模式 mode 的值可以是下列值中的一个:
| 模式 | 描述 |
|---|---|
| r | 打开一个已有的文本文件,允许读取文件。 |
| w | 打开一个文本文件,允许写入文件。如果文件不存在,则会创建一个新文件。在这里,程序会从文件的开头写入内容。如果文件存在,则该会被截断为零长度,重新写入。 |
| a | 打开一个文本文件,以追加模式写入文件。如果文件不存在,则会创建一个新文件。在这里,您的程序会在已有的文件内容中追加内容。 |
| r+ | 打开一个文本文件,允许读写文件。 |
| w+ | 打开一个文本文件,允许读写文件。如果文件已存在,则文件会被截断为零长度,如果文件不存在,则会创建一个新文件。 |
| a+ | 打开一个文本文件,允许读写文件。如果文件不存在,则会创建一个新文件。读取会从文件的开头开始,写入则只能是追加模式。 |
C 语言提供了 typedef 关键字,可以使用它来为类型取一个新的名字。下面的实例为单字节数字定义了一个术语 BYTE:
1 | typedef unsigned char BYTE; |
在这个类型定义之后,标识符 BYTE 可作为类型 unsigned char 的缩写,例如:
1 | BYTE b1, b2; |
按照惯例,定义时会大写字母,以便提醒用户类型名称是一个象征性的缩写,但您也可以使用小写字母,如下:
1 | typedef unsigned char byte; |
如果程序的结构中包含多个开关量,只有 TRUE/FALSE 变量,如下:
1 | struct |
这种结构需要 8 字节的内存空间,但在实际上,在每个变量中,只存储 0 或 1。
在这种情况下,C 语言提供了一种更好的利用内存空间的方式。如果在结构内使用这样的变量,可以定义变量的宽度来告诉编译器,将只使用这些字节。例如,上面的结构可以重写成:
1 | struct |
共用体是一种特殊的数据类型,允许您在相同的内存位置存储不同的数据类型。您可以定义一个带有多成员的共用体,但是任何时候只能有一个成员带有值。共用体提供了一种使用相同的内存位置的有效方式。
为了定义共用体,您必须使用 union 语句,方式与定义结构类似。union 语句定义了一个新的数据类型,带有多个成员。union 语句的格式如下:
1 | union [union tag] |
union tag 是可选的,每个 member definition 是标准的变量定义,比如 int i; 或者 float f; 或者其他有效的变量定义。在共用体定义的末尾,最后一个分号之前,您可以指定一个或多个共用体变量,这是可选的。下面定义一个名为 Data 的共用体类型,有三个成员 i、f 和 str:
1 | union Data |
结构体用于存储不同类型的数据项。
必须使用 struct 语句。struct 语句定义了一个包含多个成员的新的数据类型,struct 语句的格式如下:
1 | struct tag { |
tag 是结构体标签。member-list 是标准的变量定义,比如 int i; 或者 float f,或者其他有效的变量定义。variable-list 结构变量,定义在结构的末尾,最后一个分号之前,您可以指定一个或多个结构变量。下面是声明 Book 结构的方式:
1 | struct Books |
在一般情况下,tag、member-list、variable-list 这 3 部分至少要出现 2 个。
& 是取地址运算符,* 是间接运算符。
整型变量,32位CPU的话,占有32个bite。
整型指针变量,用于存放一个整型变量的地址。
解析:
从 p 处开始,先与 * 结合,所以说明 p 是一个指针, 然后再与 int 结合, 说明指针所指向的内容的类型为 int 型。
整型数据组成的数组。
解析:
首先从 p 处开始,先与 [] 结合,说明 p 是一个数组, 然后与 int 结合, 说明数组里的元素是整型的, 所以 p 是一个由整型数据组成的数组。
这是一个数组,该数组里面的成员是整型的指针,分别指向 int 型的内存。
解析:
首先从 p 处开始, 先与 [] 结合,因为其优先级比 * 高,所以 p 是一个数组, 然后再与 * 结合, 说明数组里的元素是指针类型, 然后再与 int 结合, 说明指针所指向的内容的类型是整型。
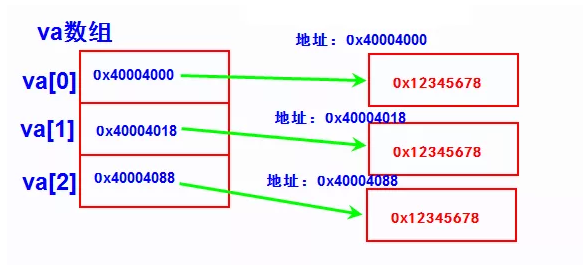
这是一个指针,指向一个 int 型数组,地址类型是int [3]型。
解析:
首先从 p 处开始, 先与 * 结合,说明 p 是一个指针然后,再与 [] 结合(与 () 这步可以忽略,只是为了改变优先级), 说明指针所指向的内容是一个数组, 然后再与 int 结合, 说明数组里的元素是整型的。

这是一个整型指针变量,用于存放一个整型变量的地址,
解析:
首先从 p 开始, 先与 * 结合, 说是 p 是一个指针, 然后再与 * 结合, 说明指针所指向的元素是指针, 然后再与 int 结合, 说明该指针所指向的元素是整型数据。
这是一个函数,函数的返回值是一个整型数据。
解析:
从 p 处起,先与 () 结合, 说明 p 是一个函数, 然后进入 () 里分析, 说明该函数有一个整型变量的参数, 然后再与外面的 int 结合, 说明函数的返回值是一个整型数据。
这是一个函数,函数的参数是 int,返回值是 void *。
这是一个指针,指向一个函数,该函数形参是 int,返回值是 int。
解析:
从 p 处开始, 先与指针结合, 说明 p 是一个指针, 然后与 () 结合, 说明指针指向的是一个函数, 然后再与 () 里的 int 结合, 说明函数有一个 int 型的参数, 再与最外层的 int 结合, 说明函数的返回类型是整型。
解析:
[3]结合,说明 p 是一个数组;p[3] 外面 * 结合,所以数组元素是一个指针;(*p[3]) 是 X,外面是 int (X)(int),所以指针是指向函数,函数的形参是 int 型,返回值是 int 型。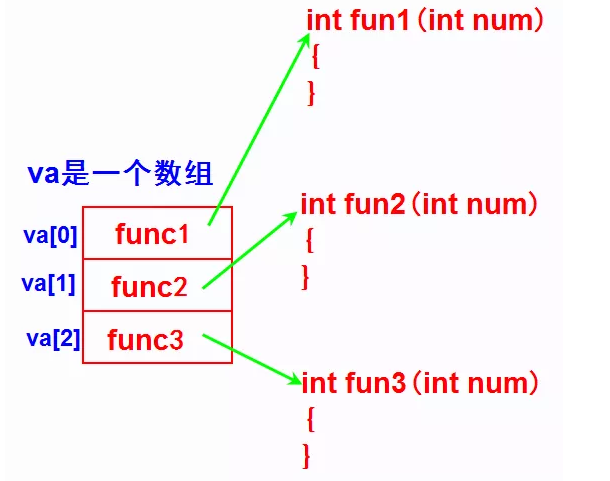
int *(*p(int))[3];解析:
从 p 开始,先与 () 结合, 说明 p 是一个函数, 然后进入 () 里面,与 int 结合, 说明函数有一个整型变量参数, 然后再与外面的 * 结合, 说明函数返回的是一个指针, 然后到最外面一层, 先与 [] 结合, 说明返回的指针指向的是一个数组, 然后再与 * 结合, 说明数组里的元素是指针, 然后再与 int 结合, 说明指针指向的内容是整型数据。
所以 p 是一个参数为一个整数,且返回一个指向由整型指针变量组成的数组的指针变量的函数。