Linux 三剑客,它们是 grep、awk、sed。
sed 全名叫 stream editor,流编辑器,用程序的方式来编辑文本,与 vim 的交互式编辑方式截然不同。它的功能十分强大,加上正则表达式的支持,可以进行大量的复杂文本的编辑操作。
使用场景:
- 自动化程序中,不适合交互方式编辑的;
- 大批量重复性的编辑需求;
- 编辑命令太过复杂,在交互文本编辑器难以输入的情况;
Linux sed 命令是利用脚本来处理文本文件。sed 命令采用的是流编辑模式,最明显的特点是,在 sed 处理数据之前,需要预先提供一组规则,sed 会按照此规则来编辑数据。默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。
默认情况下 sed 并不会修改原始文件,这里被删除的行只是从 sed 的输出中消失了,原始文件没做任何改变。
sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
- 1,每次仅读取一行内容;
- 2,根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
- 3,将执行结果输出。
工作原理
sed 作为一种非交互式编辑器,它使用预先设定好的编辑指令对输入的文本进行编辑,完成之后输出编辑结果。
简单描述 sed 工作原理:
- sed 从输入文件中读取内容,每次处理一行内容,并把当前的一行内容存储在临时的缓冲区中,称为 模式空间。
- 接着用 sed 命令处理缓存区中的内容;
- 处理完毕后,把缓存区的内容送往屏幕;
- 接着处理下一行;
这样不断重复,直到文件末尾,文件内容并没有改变,除非你使用重定向输出或指定了 i 参数
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
语法 sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
| 选项 | 含义 |
|---|---|
| -e 脚本命令 | 该选项会将其后跟的脚本命令添加到已有的命令中。 |
| -f 脚本命令文件 | 该选项会将其后文件中的脚本命令添加到已有的命令中。 |
| -n或–quiet或–silent | 仅显示script处理后的结果,默认情况下,sed 会在所有的脚本指定执行完毕后,会自动输出处理后的内容,而该选项会屏蔽启动输出,需使用 print 命令来完成输出。 |
| -h或–help | 显示帮助。 |
| -V或–version | 显示版本信息。 |
动作说明
a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)
c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
d :删除, d 后面通常不接任何字符;
i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
p :打印, 将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行
s :取代, 通常搭配正规表示法,例如 1,20s/old/new/g
正则表达式
sed 基本上就是用正则表达式模式匹配。
基本正则表达式
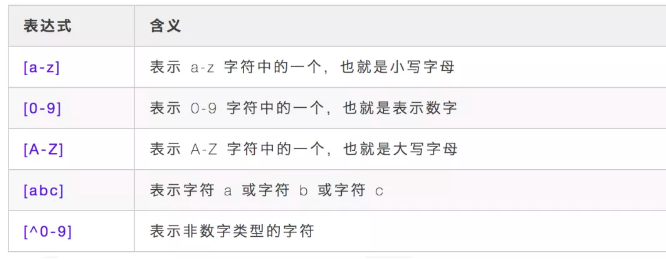
.表示匹配任意一个字符,除了换行符,类似 Shell 通配符中的 ?;*表示前边字符有 0 个或多个;.*表示任意一个字符有 0 个或多个,也就是能匹配任意的字符;^表示行首,也就是每一行的开始位置,^abc 匹配以 abc 开头的字符串;$表示行尾,也就是每一行的结尾位置,}$ 匹配以大括号结尾的字符串;{}表示前边字符的数量范围,{2},表示重复 2 次,{2,}重复至少 2次,{2,4} 重复 2-4 次;[]括号中可以包含表示字符集的表达式,使用方法大概如下几种
扩展正则表达式
扩展正则表达式使用频率上没有基本表达式那么高,但依然很重要,很多情况下没有扩展正则是搞不定的,sed 命令使用扩展正则时需要加上选项 -r。
?:表示前置字符有 0 个或 1 个;+:表示前置字符有 1 个或多个;|:表示匹配其中的一项即可;():表示分组,(a|b)b 表示可以匹配 ab 或 bb 子串,且命令表达式中可以通过 \1、\2 来表示匹配的变量{}:和基本正则中的大括号中意义相同,只不过使用时不用加 转义符号;
数字定址和正则定址
默认情况下 sed 会对每一行内容进行匹配、处理、输出,有时候我们不需要对所有内容进行操作,只需要修改一种一部分,比如 1-10 行,偶数行,或包括 hello 字符串的行。
这种情况下,就需要我们去定位特定的行来进行处理,而不是全部内容,这里把定位指定的行叫做 定址。
数字定址
数字定址其实就是通过数字去指定要操作的行,有几种方式,每种方式都有不同的应用场景。
1 | # 只将第4行中hello替换为A |
正则定址
正则定址,是通过正则表达式的匹配来确定需要处理编辑哪些行,其它行就不需要处理
1 | # 将匹配到hello的行执行删除操作,d 表示删除 |
数字定址和正则定址混用
数字定址和正则定址可以配合使用
1 | # 匹配从第1行到ts开头的行,把匹配的行执行删除 |
sed脚本命令
sed s 替换脚本命令
此命令的基本格式为:
1 | [address]s/pattern/replacement/flags |
address 表示指定要操作的具体行,pattern 指的是需要替换的内容,replacement 指的是要替换的新内容。
sed s命令flags标记及功能:
| flags 标记 | 功能 |
|---|---|
| n | 1~512 之间的数字,表示指定要替换的字符串出现第几次时才进行替换,例如,一行中有 3 个 A,但用户只想替换第二个 A,这是就用到这个标记; |
| g | 对数据中所有匹配到的内容进行替换,如果没有 g,则只会在第一次匹配成功时做替换操作。例如,一行数据中有 3 个 A,则只会替换第一个 A; |
| p | 会打印与替换命令中指定的模式匹配的行。此标记通常与 -n 选项一起使用。 |
| w file | 将缓冲区中的内容写到指定的 file 文件中; |
| & | 用正则表达式匹配的内容进行替换; |
| \n | 匹配第 n 个子串,该子串之前在 pattern 中用 \(\) 指定。 |
| \ | 转义(转义替换部分包含:& ,\ 等)。 |
实例
1 | # sed 编辑器只替换每行中第 2 次出现的匹配模式 |
sed d 替换脚本命令
基本格式为:[address]d
1 | # 删除所有内容 |
sed a 和 i 脚本命令
a 命令表示在指定行的后面附加一行,i 命令表示在指定行的前面插入一行
基本格式:[address]a(或 i)\新文本内容
1 | # 将一个新行插入到数据流第三行前 |
sed c 替换脚本命令
c 命令表示将指定行中的所有内容,替换成该选项后面的字符串。
基本格式为:[address]c\用于替换的新文本
1 | sed '3c\ |
sed y 转换脚本命令
y 转换命令是唯一可以处理单个字符的 sed 脚本命令
基本格式:[address]y/inchars/outchars/
转换命令会对 inchars 和 outchars 值进行一对一的映射,即 inchars 中的第一个字符会被转换为 outchars 中的第一个字符,第二个字符会被转换成 outchars 中的第二个字符…这个映射过程会一直持续到处理完指定字符。
如果 inchars 和 outchars 的长度不同,则 sed 会产生一条错误消息。
1 | sed 'y/123/789/' data8.txt |
sed p 打印脚本命令
p 命令表示搜索符号条件的行,并输出该行的内容
基本格式为:[address]p
1 | # p 命令常见的用法是打印包含匹配文本模式的行 |
sed w 脚本命令
w 命令用来将文本中指定行的内容写入文件中
基本格式如下:[address]w filename
filename 表示文件名,可以使用相对路径或绝对路径,运行 sed 命令的用户都必须有文件的写权限。
1 | # 将 data6.txt 1,2行打印到 test.txt |
sed r 脚本命令
r 命令用于将一个独立文件的数据插入到当前数据流的指定位置,
基本格式为:[address]r filename
1 | # sed 命令会将 filename 文件中的内容插入到 address 指定行的后面 |
sed q 退出脚本命令
q 命令的作用是使 sed 命令在第一次匹配任务结束后,退出 sed 程序,不再进行对后续数据的处理。
1 | #sed 命令在打印输出第 2 行之后,就停止 |
参考: