MongoDB 连接
标准 URI 连接语法:
1 | mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]] |
mongodb:// 这是固定的格式,必须要指定。
username:password@ 可选项,如果设置,在连接数据库服务器之后,驱动都会尝试登录这个数据库
host1 必须的指定至少一个host, host1 是这个URI唯一要填写的。它指定了要连接服务器的地址。如果要连接复制集,请指定多个主机地址。
portX 可选的指定端口,如果不填,默认为27017
/database 如果指定username:password@,连接并验证登录指定数据库。若不指定,默认打开 test 数据库。
?options 是连接选项。如果不使用
/database,则前面需要加上/。所有连接选项都是键值对name=value,键值对之间通过&或;(分号)隔开
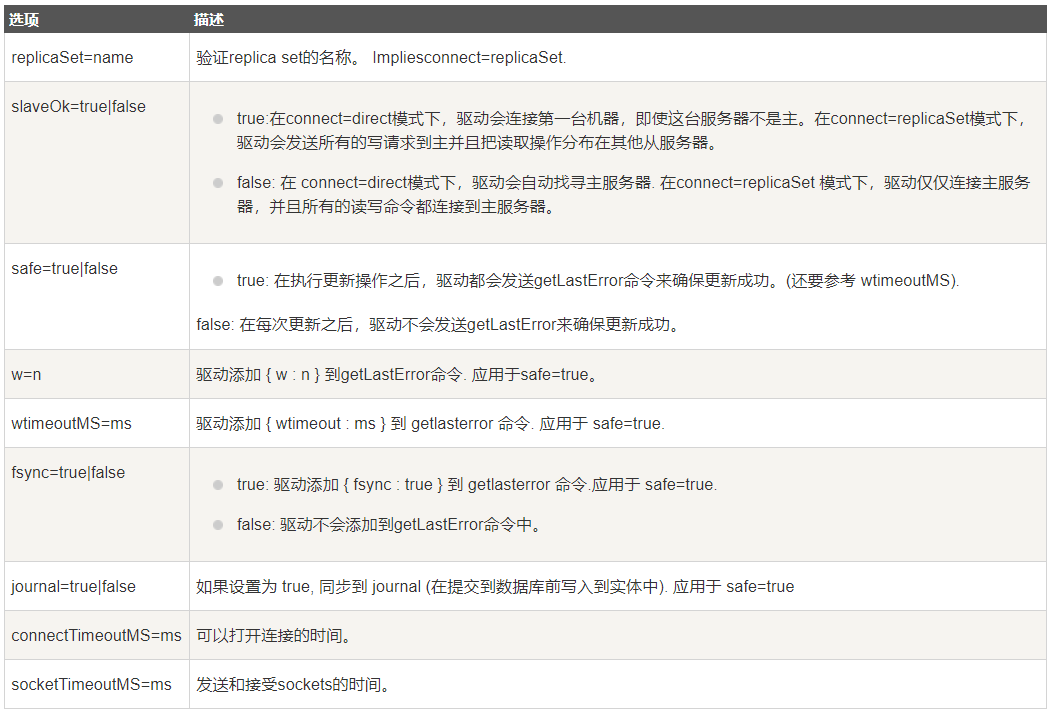
标准的连接格式包含了多个选项(options):
创建数据库
语法格式
MongoDB 创建数据库的语法格式如下:
1 | use DATABASE_NAME |
实例
1 | > use test1 |
如果数据库不存在,则创建数据库,否则切换到指定数据库。
ongoDB 中默认的数据库为 test,如果你没有创建新的数据库,集合将存放在 test 数据库中。
注意: 在 MongoDB 中,集合只有在内容插入后才会创建! 就是说,创建集合(数据表)后要再插入一个文档(记录),集合才会真正创建。
删除数据库
语法格式
MongoDB 删除数据库的语法格式如下:
1 | db.dropDatabase() |
删除当前数据库,默认为 test,你可以使用 db 命令查看当前数据库名。
实例
1 | > use test1 |
创建集合
语法格式
1 | db.createCollection(name, options) |
参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数

在插入文档时,MongoDB 首先检查固定集合的 size 字段,然后检查 max 字段。
在 MongoDB 中,你不需要创建集合。当你插入一些文档时,MongoDB 会自动创建集合。
可以使用 show collections 或 show tables 命令查看已有集合。
删除集合
语法格式:
1 | db.collection.drop() |
如果成功删除选定集合,则 drop() 方法返回 true,否则返回 false。
1 | > db.createCollection("test1") |
插入文档
所有存储在集合中的数据都是 BSON 格式。
BSON 是一种类似 JSON 的二进制形式的存储格式,是 Binary JSON 的简称。
1 | # 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据。 |
3.2 版本之后新增insertOne,insertMany
1 | # 参数说明: |
异常级别
- WriteConcern.NONE:没有异常抛出
- WriteConcern.NORMAL:仅抛出网络错误异常,没有服务器错误异常
- WriteConcern.SAFE:抛出网络错误异常、服务器错误异常;并等待服务器完成写操作。
- WriteConcern.MAJORITY: 抛出网络错误异常、服务器错误异常;并等待一个主服务器完成写操作。
- WriteConcern.FSYNC_SAFE: 抛出网络错误异常、服务器错误异常;写操作等待服务器将数据刷新到磁盘。
- WriteConcern.JOURNAL_SAFE:抛出网络错误异常、服务器错误异常;写操作等待服务器提交到磁盘的日志文件。
- WriteConcern.REPLICAS_SAFE:抛出网络错误异常、服务器错误异常;等待至少2台服务器完成写操作。
更新文档
update() 方法
语法格式
1 | db.collection.update( |
参数说明:
- query : update的查询条件,类似sql update查询内where后面的。
- update : update的对象和一些更新的操作符(如$,$inc…)等,也可以理解为sql update查询内set后面的
- upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
- multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
实例
1 | db.test1.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}}) |
save() 方法
save() 方法通过传入的文档来替换已有文档,_id 主键存在就更新,不存在就插入。
语法格式如下:
1 | db.collection.save( |
参数说明:
- document : 文档数据。
- writeConcern :可选,抛出异常的级别。
在3.2版本开始,MongoDB提供以下更新集合文档的方法:
1 | # 向指定集合更新单个文档 |
删除文档
MongoDB 最早删除文档使用的是 remove() 方法,后来官方把它移除了因为 remove() 并不会真正释放空间。需要继续执行 db.repairDatabase() 来回收磁盘空间。
建议在执行删除文档函数前先执行 find() 命令来判断执行的条件是否正确 db.test1.find() 。
1 | db.repairDatabase() |
官方推荐使用 deleteOne() 和 deleteMany() 方法。
语法
deleteOne() 语法:
1 | db.collection.deleteOne( |
deleteMany() 语法:
1 | db.collection.deleteMany( |
1 | # 删除集合下全部文档 |
查询文档
MongoDB 查询文档使用 find(), findOne() 方法。
find() 方法以非结构化的方式来显示所有文档。
语法格式
db.collection.find(query, projection)
- query :可选,使用查询操作符指定查询条件
- projection :可选,使用投影操作符指定返回的键。若不指定 projection,则默认返回所有键(默认省略)。
1 | # projection入参格式为{columnA : 0/1,columnB : 0/1} |
如:{title:1},表示查询出的每条记录中只显示 title 字段内容。{description:0},表示查询出的每条记录中不显示 description 字段内容(其他字段都展示)。
注:_id(主键)字段默认为 1,可指定 {_id:0} 来不输出 _id 字段值。
指定 projection 格式如下,有两种模式
1 | db.collection.find(query, {title: 1, by: 1}) // inclusion模式 指定返回的键,不返回其他键 |
两种模式不可混用(因为这样的话无法推断其他键是否应返回)
1 | db.collection.find(query, {title: 1, by: 0}) # 错误 |
若不想指定查询条件参数 query 可以 用 {} 代替,但是需要指定 projection 参数:
1 | querydb.collection.find({}, {title: 1}) |
AND 条件
1 | db.test1.find({key1:value1, key2:value2}).pretty() |
OR 条件
使用关键字 $or,语法格式如下:
1 | db.test1.find( |
AND 和 OR 联合使用
where likes>50 AND (by = 'test1' OR title = 'MongoDB')
1 | db.test1.find({"likes": {$gt:50}, $or: [{"by": "test1"},{"title": "MongoDB"}]}).pretty() |
模糊查询
1 | # 查询 title 包含"教"字的文档: |
条件操作符
结合查询语句使用。
- $gt — greater than >
- $gte — gt equal >=
- $lt — less than <
- $lte — lt equal <=
- $ne — not equal !=
- $eq — equal =
$type 操作符
$type 操作符是基于BSON类型来检索集合中匹配的数据类型,并返回结果。
获取 test1 集合中 title 为 String 的数据
1 | db.test1.find({"title" : {$type : 2}}) |
Limit与Skip方法
1 | # Limit() 方法 |
skip 和limit方法只适合小数据量分页,如果是百万级效率就会非常低,因为skip方法是一条条数据数过去的,建议使用 where limit。
排序
sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
语法:
1 | # 语法 |
索引
3.0.0 版本前创建索引方法为 db.collection.ensureIndex() ,之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。
语法
1 | db.collection.createIndex(keys, options) |
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引 -1 按降序来创建索引。
可选参数:

1 | # 查看集合索引 |
TTL索引
保存最近三个月的文档(单位秒),当中途修改了createdAt的值时,
则不会删除文档(指定的时间是字段与当前时间的差值)。
db.user.createIndex({"createdAt": 1},{expireAfterSeconds: 60*60*24*3});
若需求变动,需要将三个月修改为一个月可以使用collMod,如下:
db.runCommand({collMod: 'user', index: {keyPattern:{"createdAt": 1}, expireAfterSeconds:60*60*24*1}});
TTL索引限制:
- TTL索引是单字段索引,不能使用在聚合索引上
- 不能在普通索引上再创建TTL索引,只能删除再建
- _id主键上不能建立TTL索引
- 一个集合上可以建立多个TTL索引
- 索引不能包含多个字段
- TTL索引可以用于普通索引一样进行排序和查询
- 如果定义的字段不存在,则永不过期
- 不能对capped集合创建TTL索引
- TTL索引会每分钟检查超时文档,并进行删除操作。需要注意删除时候的并发问题(不要影响线上业务)
聚合
MongoDB中聚合( aggregate )主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
aggregate() 方法
db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
聚合的表达式:
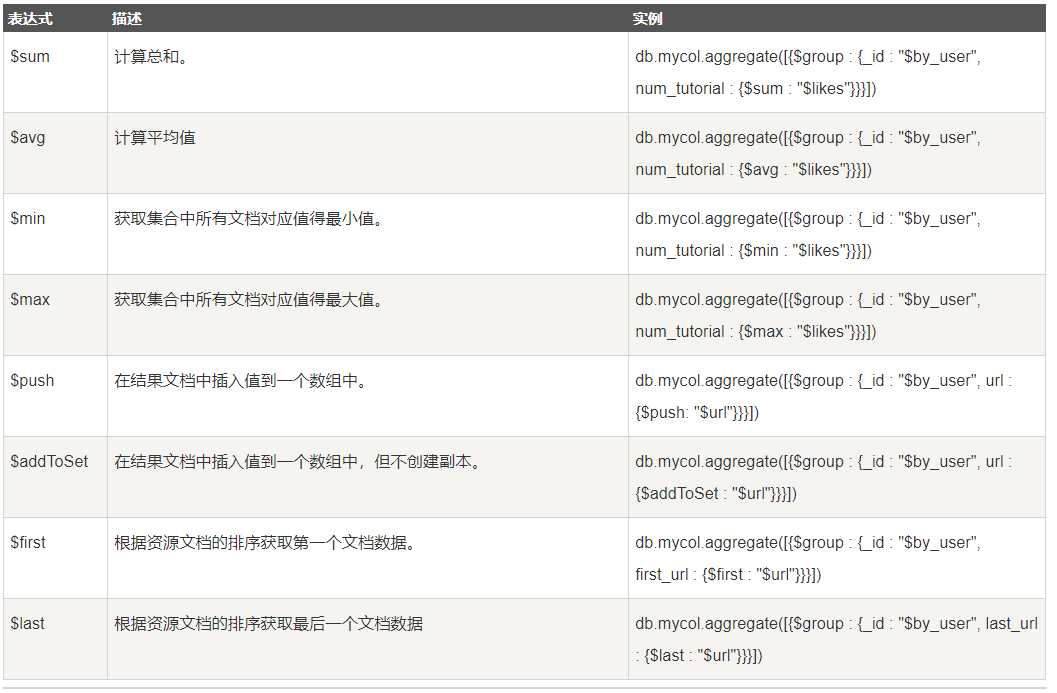
实例:
1 | db.test1.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}]) |
管道操作
MongoDB 的聚合管道将 MongoDB 文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。
$match使用MongoDB的标准查询操作。 - $limit:用来限制
MongoDB聚合管道返回的文档数。 - $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
注意:当 match 条件和 group 同时存在时,顺序会影响检索结果,必须先写 match 在前面。
时间关键字如下:
- $dayOfYear: 返回该日期是这一年的第几天(全年 366 天)。
- $dayOfMonth: 返回该日期是这一个月的第几天(1到31)。
- $dayOfWeek: 返回的是这个周的星期几(1:星期日,7:星期六)。
- $year: 返回该日期的年份部分。
- $month: 返回该日期的月份部分( 1 到 12)。
- $week: 返回该日期是所在年的第几个星期( 0 到 53)。
- $hour: 返回该日期的小时部分。
- $minute: 返回该日期的分钟部分。
- $second: 返回该日期的秒部分(以0到59之间的数字形式返回日期的第二部分,但可以是60来计算闰秒)。
- $millisecond:返回该日期的毫秒部分( 0 到 999)。
- $dateToString: { $dateToString: { format: , date: } }。
实例:
1 | db.getCollection('m_msg_tb').aggregate( |
参考: