MongoDB基本概念
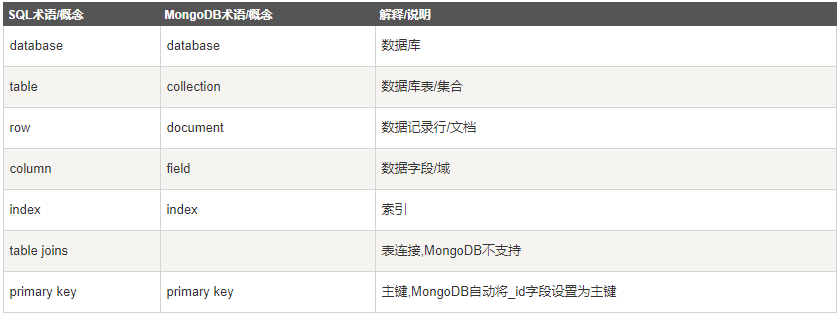
1 | # 可以显示所有数据的列表 |
数据库也通过名字来标识。数据库名可以是满足以下条件的任意 UTF-8 字符串。
- 不能是空字符串(””)。
- 不得含有’ ‘(空格)、.、$、/、\和\0 (空字符)。
- 应全部小写。
- 最多64字节。
有一些数据库名是保留的,可以直接访问这些有特殊作用的数据库。
- admin: 从权限的角度来看,这是
root数据库。要是将一个用户添加到这个数据库,这个用户自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或者关闭服务器。 - local: 这个数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合
- config: 当Mongo用于分片设置时,
config数据库在内部使用,用于保存分片的相关信息。
文档(Document)
RDBMS (关系数据库管理系统:Relational Database Management System) 与 MongoDB 对应的术语:
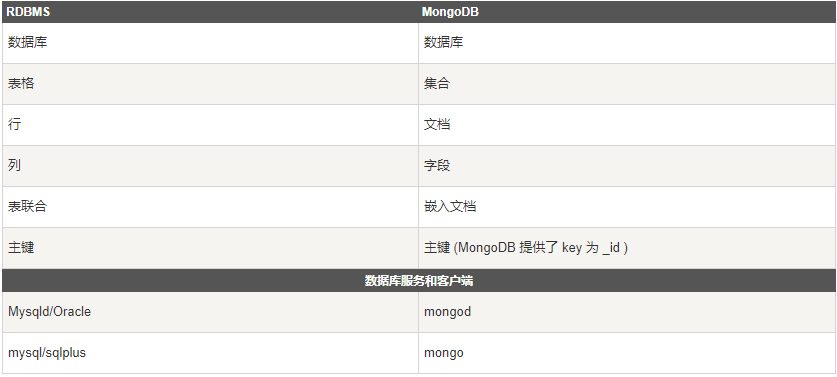
需要注意的是:
- 文档中的键/值对是有序的。
- 文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。
- MongoDB区分类型和大小写。
- MongoDB的文档不能有重复的键。
- 文档的键是字符串。除了少数例外情况,键可以使用任意UTF-8字符。
文档键命名规范:
- 键不能含有\0 (空字符)。这个字符用来表示键的结尾。
- .和$有特别的意义,只有在特定环境下才能使用。
- 以下划线”_”开头的键是保留的(不是严格要求的)。
集合
当第一个文档插入时,集合就会被创建。
合法的集合名
- 集合名不能是空字符串””。
- 集合名不能含有\0字符(空字符),这个字符表示集合名的结尾。
- 集合名不能以”system.”开头,这是为系统集合保留的前缀。
- 用户创建的集合名字不能含有保留字符。有些驱动程序的确支持在集合名里面包含,这是因为某些系统生成的集合中包含该字符。除非你要访问这种系统创建的集合,否则千万不要在名字里出现$。
capped collections
名词解释:
capped:用…覆盖顶部(或端部)
Capped collections 就是固定大小的 collection。
它有很高的性能以及队列过期的特性(过期按照插入的顺序). 有点和 “RRD” 概念类似(round robin database,即环形数据库)。
Capped collections 是高性能自动的维护对象的插入顺序。它非常适合类似记录日志的功能和标准的 collection 不同,你必须要显式的创建一个 capped collection,指定一个 collection 的大小,单位是字节。collection 的数据存储空间值提前分配的。
Capped collections 可以按照文档的插入顺序保存到集合中,而且这些文档在磁盘上存放位置也是按照插入顺序来保存的,所以当我们更新 Capped collections 中文档的时候,更新后的文档不可以超过之前文档的大小,这样话就可以确保所有文档在磁盘上的位置一直保持不变。
由于 Capped collection 是按照文档的插入顺序而不是使用索引确定插入位置,这样的话可以提高增添数据的效率。MongoDB 的操作日志文件 oplog.rs 就是利用 Capped Collection 来实现的。
要注意的是指定的存储大小包含了数据库的头信息。
db.createCollection("mycoll", {capped:true, size:100000})
size 是整个集合空间大小,单位为【KB】
max 是集合文档个数上线,单位是【个】
如果空间大小到达上限,则插入下一个文档时,会覆盖第一个文档;如果文档个数到达上限,同样插入下一个文档时,会覆盖第一个文档。
两个参数上限判断取的是【与】的逻辑。
- 在 capped collection 中,你能添加新的对象。
- 能进行更新,然而,对象不会增加存储空间。如果增加,更新就会失败 。
- 使用 Capped Collection 不能删除一个文档,可以使用
drop()方法删除collection所有的行。 - 删除之后,你必须显式的重新创建这个
collection。 - 在 32位机器中,capped collection 最大存储为 1e9( 1X109)个字节,约为482.5M,64位上只受系统文件大小的限制。。
- 对固定集合进行插入速度极快
- 按照插入顺序的查询输出速度极快
- 能够在插入最新数据时,淘汰最早的数据
用法
用法1:储存日志信息
用法2:缓存一些少量的文档
元数据
数据库的信息是存储在集合中。它们使用了系统的命名空间:
dbname.system.*
在MongoDB数据库中名字空间 <dbname>.system.* 是包含多种系统信息的特殊集合 (Collection),如下:
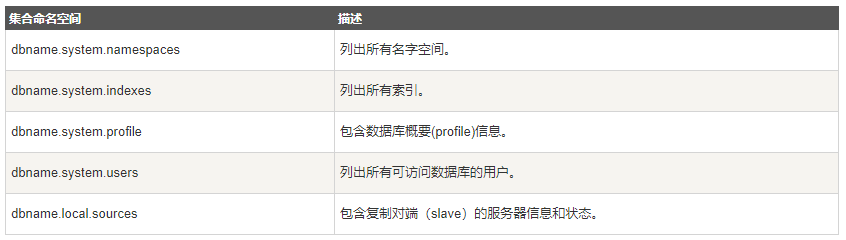
对于修改系统集合中的对象有如下限制。
1 | 在 {{system.indexes}} 插入数据,可以创建索引。 |
MongoDB 数据类型

ObjectId
ObjectId 类似唯一主键,可以很快的去生成和排序,包含 12 bytes,含义是:
- 前 4 个字节表示创建 unix 时间戳,格林尼治时间 UTC 时间,比北京时间晚了 8 个小时
- 接下来的 3 个字节是机器标识码
- 紧接的两个字节由进程 id 组成 PID
- 最后三个字节是随机数
MongoDB 中存储的文档必须有一个 _id 键。这个键的值可以是任何类型的,默认是个 ObjectId对象
由于 ObjectId 中保存了创建的时间戳,所以你不需要为你的文档保存时间戳字段,你可以通过 getTimestamp 函数来获取文档的创建时间:
1 | > var newObject = ObjectId() |
字符串
BSON 字符串都是 UTF-8 编码。
时间戳
BSON 有一个特殊的时间戳类型用于 MongoDB 内部使用,与普通的 日期 类型不相关。 时间戳值是一个 64 位的值。其中:
前32位是一个 time_t 值(与Unix新纪元相差的秒数)
后32位是在某秒中操作的一个递增的序数
在单个 mongod 实例中,时间戳值通常是唯一的。
在复制集中, oplog 有一个 ts 字段。这个字段中的值使用BSON时间戳表示了操作时间。
BSON 时间戳类型主要用于 MongoDB 内部使用。在大多数情况下的应用开发中,你可以使用 BSON 日期类型。
日期
表示当前距离 Unix新纪元(1970年1月1日)的毫秒数。日期类型是有符号的, 负数表示 1970 年之前的日期。
1 | > var mydate1 = new Date() //格林尼治时间 |
这样创建的时间是日期类型,可以使用 JS 中的 Date 类型的方法。
返回一个时间类型的字符串:
1 | > var mydate1str = mydate1.toString() |
参考: