属性 TPL Dataflow 是微软面向高并发应用而推出的一个类库。借助于异步消息传递与管道,它可以提供比线程池更好的控制,也比手工线程方式具备更好的性能。我们常常可以消息传递,生产-消费模式或Actor-Agent模式中使用。在TDF是构建于 Task Parallel Library (TPL)之上的,它是我们开发高性能,高并发的应用程序的又一利器。
TDF的主要作用就是 Buffering Data 和 Processing Data ,在TDF中,有两个非常重要的接口,ISourceBlock<T> 和 ITargetBlock<T> 接口。继承于 ISourceBlock<T> 的对象时作为提供数据的数据源对象-生产者,而继承于 ITargetBlock<T> 接口类主要是扮演目标对象-消费者。在这个类库中,System.Threading.Tasks.Dataflow 名称空间下,提供了很多以Block名字结尾的类,ActionBlock,BufferBlock,TransformBlock,BroadcastBlock 等9个Block,我们在开发中通常使用单个或多个Block组合的方式来实现一些功能。
支持的版本:
备注:
TPL 数据流库(System.Threading.Tasks.Dataflow 命名空间)不随 .NET 一起分发。 若要在 Visual Studio 中安装 System.Threading.Tasks.Dataflow 命名空间,请打开项目,选择“项目” 菜单中的“管理 NuGet 包” ,再在线搜索 System.Threading.Tasks.Dataflow 包。 或者,若要使用 .NET Core CLI 进行安装,请运行 dotnet add package System.Threading.Tasks.Dataflow。
BufferBlock
BufferBlock 是TDF中最基础的 Block。BufferBlock 提供了一个有界限或没有界限的 Buffer,该 Buffer 中存储T。该 Block 很像 BlockingCollection<T> 。可以用过 Post 往里面添加数据,也可以通过Receive 方法阻塞或异步的的获取数据,数据处理的顺序是 FIFO 的。它也可以通过Link向其他 Block 输出数据。
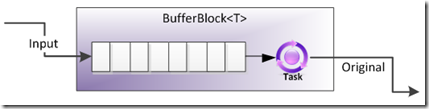
简单的同步的生产者消费者代码示例:
1 | private static BufferBlock<int> m_buffer = new BufferBlock<int>(); |
ActionBlock
ActionBlock 实现 ITargetBlock,说明它是消费数据的,也就是对输入的一些数据进行处理。它在构造函数中,允许输入一个委托,来对每一个进来的数据进行一些操作。如果使用Action(T) 委托,那说明每一个数据的处理完成需要等待这个委托方法结束,如果使用了 Func<TInput, Task>) 来构造的话,那么数据的结束将不是委托的返回,而是Task的结束。默认情况下,ActionBlock 会 FIFO 的处理每一个数据,而且一次只能处理一个数据,一个处理完了再处理第二个,但也可以通过配置来并行的执行多个数据。

1 | public ActionBlock<int> abSync = new ActionBlock<int>((i) => |
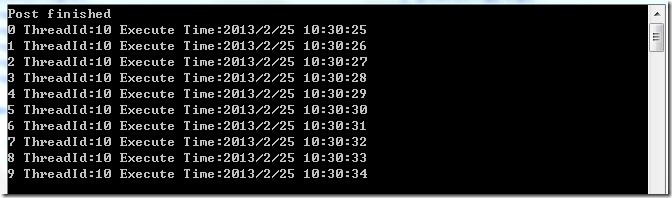
可见,ActionBlock 是顺序处理数据的,这也是 ActionBlock 一大特性之一。主线程在往 ActionBlock 中 Post 数据以后马上返回,具体数据的处理是另外一个线程来做的。数据是异步处理的,但处理本身是同步的,这样在一定程度上保证数据处理的准确性。下面的例子是使用async和await。
1 | public ActionBlock<int> abSync2 = new ActionBlock<int>(async (i) => |
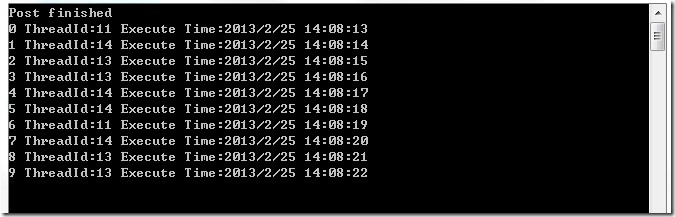
虽然还是1秒钟处理一个数据,但是处理数据的线程会有不同。
如果你想异步处理多个消息的话,ActionBlock 也提供了一些接口,让你轻松实现。在 ActionBlock 的构造函数中,可以提供一个 ExecutionDataflowBlockOptions 的类型,让你定义 ActionBlock 的执行选项,在下面了例子中,我们定义了 MaxDegreeOfParallelism 选项,设置为3。目的的让 ActionBlock 中的Item最多可以3个并行处理。
1 | public ActionBlock<int> abAsync = new ActionBlock<int>((i) => |
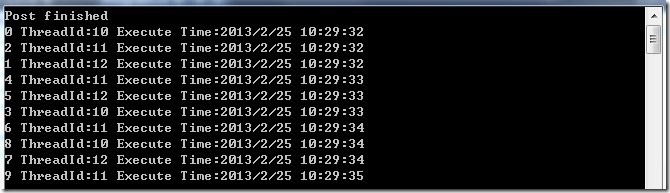
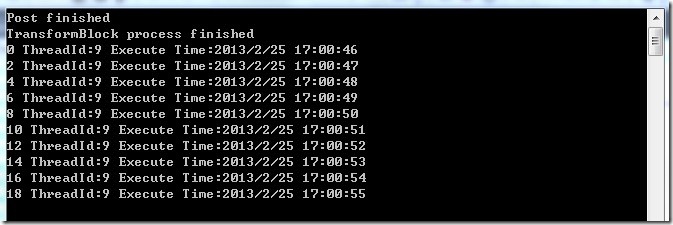
运行程序,我们看见,每3个数据几乎同时处理,并且他们的线程ID也是不一样的。
ActionBlock 也有自己的生命周期,所有继承 IDataflowBlock 的类型都有 Completion 属性和 Complete 方法。调用 Complete 方法是让 ActionBlock 停止接收数据,而 Completion 属性则是一个Task,是在 ActionBlock 处理完所有数据时候会执行的任务,我们可以使用 Completion.Wait() 方法来等待 ActionBlock 完成所有的任务,Completion 属性只有在设置了 Complete 方法后才会有效。
1 | public void TestAsync() |
TransformBlock
TransformBlock 是TDF提供的另一种 Block ,顾名思义它常常在数据流中充当数据转换处理的功能。在TransformBlock 内部维护了2个 Queue,一个 InputQueue,一个 OutputQueue。InputQueue 存储输入的数据,而通过 Transform 处理以后的数据则放在 OutputQueue,OutputQueue 就好像是一个 BufferBlock。最终我们可以通过 Receive 方法来阻塞的一个一个获取 OutputQueue 中的数据。 TransformBlock 的 Completion.Wait() 方法只有在 OutputQueue 中的数据为0的时候才会返回。

举个例子,我们有一组网址的URL,我们需要对每个URL下载它的HTML数据并存储。那我们通过如下的代码来完成:
1 | public TransformBlock<string, string> tbUrl = new TransformBlock<string, string>((url) => |
当然,Post 操作和 Receive 操作可以在不同的线程中进行,Receive 操作同样也是阻塞操作,在 OutputQueue 中有可用的数据时,才会返回。
TransformManyBlock
TransformManyBlock 和 TransformBlock 非常类似,关键的不同点是,TransformBlock 对应于一个输入数据只有一个输出数据,而 TransformManyBlock 可以有多个,及可以从 InputQueue 中取一个数据出来,然后放多个数据放入到 OutputQueue 中。

1 | TransformManyBlock<int, int> tmb = new TransformManyBlock<int, int>((i) => { return new int[] { i, i + 1 }; }); |

BroadcastBlock
BroadcastBlock 的作用不像 BufferBlock ,它是使命是让所有和它相联的目标 Block 都收到数据的副本,这点从它的命名上面就可以看出来了。还有一点不同的是,BroadcastBlock 并不保存数据,在每一个数据被发送到所有接收者以后,这条数据就会被后面最新的一条数据所覆盖。如没有目标 Block 和 BroadcastBlock 相连的话,数据将被丢弃。但 BroadcastBlock 总会保存最后一个数据,不管这个数据是不是被发出去过,如果有一个新的目标 Block 连上来,那么这个 Block 将收到这个最后一个数据。
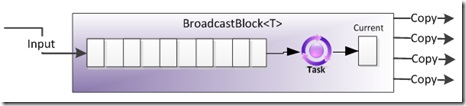
1 | BroadcastBlock<int> bb = new BroadcastBlock<int>((i) => { return i; }); |

如果我们在Post以后再添加连接Block的话,那些Block就只会收到最后一个数据了。
1 | public void TestSync() |
WriteOnceBlock
如果说 BufferBlock 是最基本的 Block ,那么 WriteOnceBock 则是最最简单的 Block 。它最多只能存储一个数据,一旦这个数据被发送出去以后,这个数据还是会留在Block中,但不会被删除或被新来的数据替换,同样所有的接收者都会收到这个数据的备份。
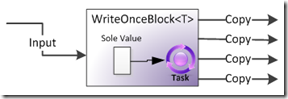
和BroadcastBlock同样的代码,但是结果不一样:
1 | WriteOnceBlock<int> bb = new WriteOnceBlock<int>((i) => { return i; }); |

WriteOnceBock只会接收一次数据。而且始终保留那个数据。
同样使用Receive方法来获取数据也是一样的结果,获取到的都是第一个数据:
1 | public void TestReceive() |

BatchBlock

BatchBlock 提供了能够把多个单个的数据组合起来处理的功能,如上图。应对有些需求需要固定多个数据才能处理的问题。在构造函数中需要制定多少个为一个 Batch,一旦它收到了那个数量的数据后,会打包放在它的 OutputQueue 中。当 BatchBlock 被调用 Complete 告知 Post 数据结束的时候,会把 InputQueue 中余下的数据打包放入 OutputQueue 中等待处理,而不管 InputQueue 中的数据量是不是满足构造函数的数量。
1 | BatchBlock<int> bb = new BatchBlock<int>(3); |

BatchBlock 执行数据有两种模式:贪婪模式和非贪婪模式。贪婪模式是默认的。贪婪模式是指任何Post到BatchBlock,BatchBlock 都接收,并等待个数满了以后处理。非贪婪模式是指 BatchBlock 需要等到构造函数中设置的 BatchSize 个数的 Source 都向 BatchBlock 发数据,Post 数据的时候才会处理。不然都会留在Source的Queue中。也就是说 BatchBlock 可以使用在每次从N个 Source 那个收一个数据打包处理或从1个 Source 那里收N个数据打包处理。这里的Source是指其他的继承 ISourceBlock 的,用 LinkTo 连接到这个BatchBlock 的 Block 。
在另一个构造参数中 GroupingDataflowBlockOptions,可以通过设置 Greedy 属性来选择是否贪婪模式和 MaxNumberOfGroups 来设置最大产生Batch的数量,如果到达了这个数量,BatchBlock 将不会再接收数据。
JoinBlock

JoinBlock 一看名字就知道是需要和两个或两个以上的 Source Block 相连接的。它的作用就是等待一个数据组合,这个组合需要的数据都到达了,它才会处理数据,并把这个组合作为一个 Tuple 传递给目标 Block。举个例子,如果定义了 JoinBlock<int, string> 类型,那么 JoinBlock 内部会有两个 ITargetBlock,一个接收int类型的数据,一个接收string类型的数据。那只有当两个 ITargetBlock 都收到各自的数据后,才会放到JoinBlock的OutputQueue 中,输出。
1 | JoinBlock<int, string> jb = new JoinBlock<int, string>(); |

BatchedJoinBlock

BatchedJoinBlock 一看就是 BacthBlock 和 JoinBlick 的组合。JoinBlick 是组合目标队列的一个数据,而 BatchedJoinBlock 是组合目标队列的N个数据,当然这个N可以在构造函数中配置。如果我们定义的是BatchedJoinBlock<int, string>, 那么在最后的 OutputQueue 中存储的是 Tuple<IList<int>, IList<string>>,也就是说最后得到的数据是 Tuple<IList<int>, IList<string>>。它的行为是这样的,还是假设上文的定义,BatchedJoinBlock<int, string>, 构造 BatchSize 输入为3。那么在这个BatchedJoinBlock 种会有两个 ITargetBlock,会接收Post的数据。那什么时候会生成一个 Tuple<IList<int>,IList<string>> 到 OutputQueue 中呢,测试下来并不是我们想的需要有3个int数据和3个string数据,而是只要2个 ITargetBlock 中的数据个数加起来等于3就可以了。3和0,2和1,1和2或0和3的组合都会生成 Tuple<IList<int>,IList<string>> 到 OutputQueue 中。可以参看下面的例子:
1 | BatchedJoinBlock<int, string> bjb = new BatchedJoinBlock<int, string>(3); |
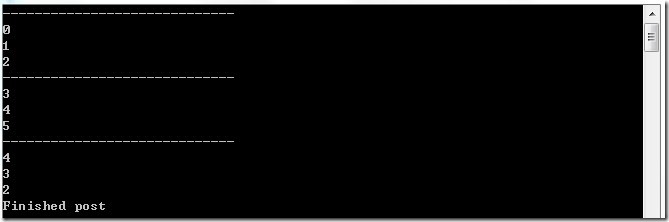
最后剩下的一个数据1,由于没有满3个,所以一直被保留在Target2中。
TDF中最有用的功能之一就是多个 Block 之间可以组合应用。ISourceBlock 可以连接 ITargetBlock ,一对一,一对多,或多对多。下面的例子就是一个 TransformBlock 和一个 ActionBlock 的组合。TransformBlock 用来把数据*2,并转换成字符串,然后把数据扔到 ActionBlock 中,而 ActionBlock 则用来最后的处理数据打印结果。
1 | public ActionBlock<string> abSync = new ActionBlock<string>((i) => |
参考: