线程基础
进程与线程
我们运行一个exe,就是一个进程实例,系统中有很多个进程。每一个进程都有自己的内存地址空间,每个进程相当于一个独立的边界,有自己的独占的资源,进程之间不能共享代码和数据空间。
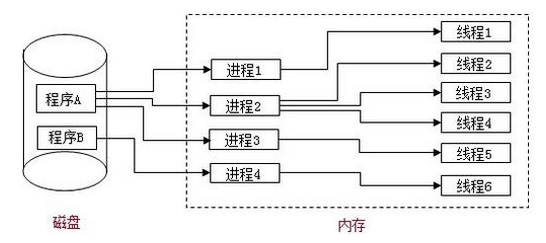
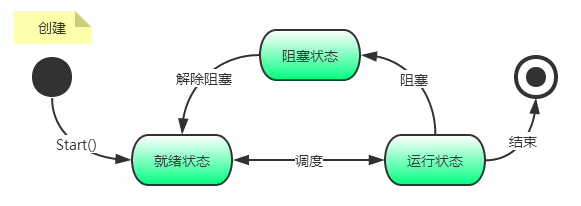
每一个进程有一个或多个线程,进程内多个线程可以共享所属进程的资源和数据,线程是操作系统调度的基本单元。线程是由操作系统来调度和执行的,她的基本状态如下图。
线程的开销及调度
创建一个线程,主要包括线程内核对象、线程环境块、1M大小的用户模式栈、内核模式栈。其中用户模式栈对于普通的系统线程那1M是预留的,在需要的时候才会分配,但是对于CLR线程,那1M是一开始就分类了内存空间的。

操作系统中那么多线程(一般都有上千个线程,大部分都处于休眠状态),对于单核CPU,一次只能有一个线程被调度执行,那么多线程怎么分配的呢?Windows系统采用时间轮询机制,CPU计算资源以时间片(大约30ms)的形式分配给执行线程。
计算机资源(CPU核心和CPU寄存器)一次只能调度一个线程,具体的调度流程:
- 把CPU寄存器内的数据保存到当前线程内部(线程上下文等地方),给下一个线程腾地方;
- 线程调度:在线程集合里取出一个需要执行的线程;
- 加载新线程的上下文数据到CPU寄存器;
- 新线程执行,享受她自己的CPU时间片(大约30ms),完了之后继续回到第一步,继续轮回;
上面线程调度的过程,就是一次线程切换,一次切换就涉及到线程上下文等数据的搬入搬出,性能开销是很大的。因此线程不可滥用,线程的创建和消费也是很昂贵的,这也是为什么建议尽量使用线程池的一个主要原因。
线程的主要几点性能影响:
- 线程的创建、销毁都是很昂贵的;
- 线程上下文切换有极大的性能开销,当然假如需要调度的新线程与当前是同一线程的话,就不需要线程上下文切换了,效率要快很多;
- GC执行回收时,首先要(安全的)挂起所有线程,遍历所有线程栈(根),GC回收后更新所有线程的根地址,再恢复线程调用,线程越多,GC要干的活就越多;
多线程
线程池(ThreadPool)
将任务添加进线程池:
1 | ThreadPool.QueueUserWorkItem(new WaitCallback(方法名)); |
因为ThreadPool是静态类 所以不需要实例化.
每个CLR都有一个线程池,线程池在CLR内可以多个AppDomain共享,线程池是CLR内部管理的一个线程集合,初始是没有线程的,在需要的时候才会创建。
基本流程如下:
- 线程池内部维护一个请求列队,用于缓存用户请求需要执行的代码任务,就是ThreadPool.QueueUserWorkItem提交的请求;
- 有新任务后,线程池使用空闲线程或新线程来执行队列请求;
- 任务执行完后线程不会销毁,留着重复使用;
- 线程池自己负责维护线程的创建和销毁,当线程池中有大量闲置的线程时,线程池会自动结束一部分多余的线程来释放资源;
1 | using System; |
AutoResetEvent和ManualResetEvent区别:
AutoResetEvent的WaitOne()方法执行后会自动又将信号置为不发送状态也就是阻塞状态,当再次遇到WaitOne()方法是又会被阻塞,而ManualResetEvent则不会,只要线程处于非阻塞状态则无论遇到多少次WaitOne()方法都不会被阻塞,除非调用ReSet()方法来手动阻塞线程。
线程池是有一个容量的,可以设置线程池的最大活跃线程数,调用方法ThreadPool.SetMaxThreads可以设置相关参数。但很多编程实践里都不建议程序猿们自己去设置这些参数,其实微软为了提高线程池性能,做了大量的优化,线程池可以很智能的确定是否要创建或是消费线程,大多数情况都可以满足需求了。
线程池使得线程可以充分有效地被利用,减少了任务启动的延迟,也不用大量的去创建线程,避免了大量线程的创建和销毁对性能的极大影响。
线程池的不足:
- 线程池内的线程不支持线程的挂起、取消等操作,如想要取消线程里的任务,.NET支持一种协作式方式取消,使用起来也不很方便,而且有些场景并不满足需求;
- 线程内的任务没有返回值,也不知道何时执行完成;
- 不支持设置线程的优先级,还包括其他类似需要对线程有更多的控制的需求都不支持;
任务Task与并行Parallel
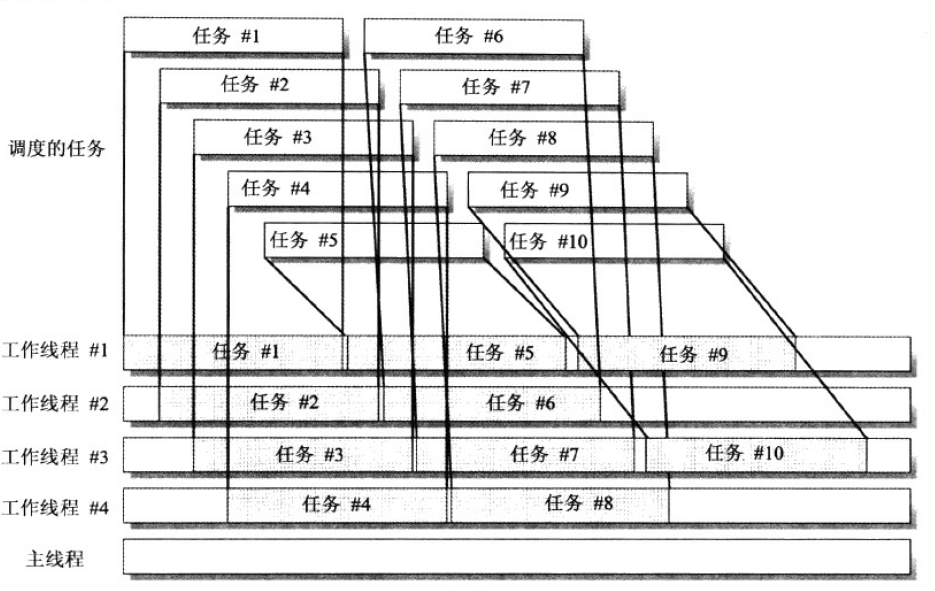
任务Task与并行Parallel本质上内部都是使用的线程池,提供了更丰富的并行编程的方式。任务Task基于线程池,可支持返回值,支持比较强大的任务执行计划定制等功能。
1 | //创建一个任务 |
并行Parallel内部其实使用的是Task对象(TPL会在内部创建System.Threading.Tasks.Task的实例),所有并行任务完成后才会返回。少量短时间任务建议就不要使用并行Parallel了,并行Parallel本身也是有性能开销的,而且还要进行并行任务调度、创建调用方法的委托等等。
GUI线程处理模型
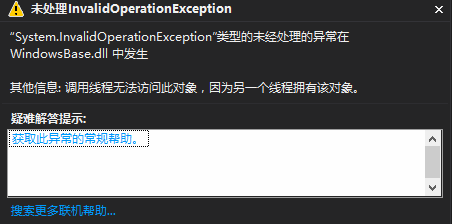
这是很多开发C/S客户端应用程序会遇到的问题,GUI程序的界面控件不允许跨线程访问,如果在其他线程中访问了界面控件,运行时就会抛出一个异常,就像下面的图示,是不是很熟悉!这其中的罪魁祸首就是,就是“GUI的线程处理模型”。
.NET支持多种不同应用程序模型,大多数的线程都是可以做任何事情(他们可能没有引入线程模型),但GUI应用程序(主要是Winform、WPF)引入了一个特殊线程处理模型,UI控件元素只能由创建它的线程访问或修改,微软这样处理是为了保证UI控件的线程安全。
为什么在UI线程中执行一个耗时的计算操作,会导致UI假死呢?这个问题要追溯到Windows的消息机制了。
因为Windows是基于消息机制的,我们在UI上所有的键盘、鼠标操作都是以消息的形式发送给各个应用程序的。GUI线程内部就有一个消息队列,GUI线程不断的循环处理这些消息,并根据消息更新UI的呈现。如果这个时候,你让GUI线程去处理一个耗时的操作(比如花10秒去下载一个文件),那GUI线程就没办法处理消息队列了,UI界面就处于假死的状态。
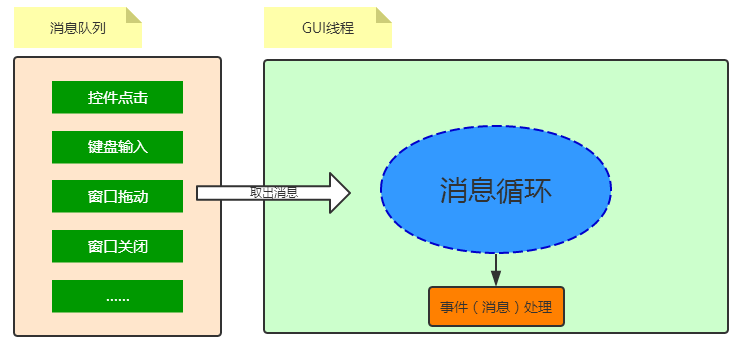
在线程里处理事件完成后,需要更新UI控件的状态:
(1)使用GUI控件提供的方法,Winform是控件的Invoke方法,WPF中是控件的Dispatcher.Invoke方法
1 | //1.Winform:Invoke方法和BeginInvoke |
(2)使用.NET中提供的BackgroundWorker执行耗时计算操作,在其任务完成事件RunWorkerCompleted 中更新UI控件
1 | using (BackgroundWorker bw = new BackgroundWorker()) |
(3)使用GUI线程处理模型的同步上下文来送封UI控件修改操作,这样可以不需要调用UI控件元素
.NET中提供一个用于同步上下文的类SynchronizationContext,利用它可以把应用程序模型链接到他的线程处理模型,其实它的本质还是调用的第一步(1)中的方法。
实现代码分为三步,第一步定义一个静态类,用于GUI线程的UI元素访问封装:
1 | public static class GUIThreadHelper |
第二步,在主窗口注册当前SynchronizationContext:
1 | public partial class MainWindow : Window |
第三步,就是使用了,可以在任何地方使用
1 | GUIThreadHelper.SyncContextCallback(() => |
线程同步构造
基元线程同步构造分为:基元用户模式构造和基元内核模式构造,两种同步构造方式各有优缺点,而混合构造(如lock)就是综合两种构造模式的优点。
用户模式构造
基元用户模式比基元内核模式速度要快,她使用特殊的cpu指令来协调线程,在硬件中发生,速度很快。但也因此Windows操作系统永远检测不到一个线程在一个用户模式构造上阻塞了。举个例子来模拟一下用户模式构造的同步方式:
- 线程1请求了临界资源,并在资源门口使用了用户模式构造的锁;
- 线程2请求临界资源时,发现有锁,因此就在门口等待,并不停的去询问资源是否可用;
- 线程1如果使用资源时间较长,则线程2会一直运行,并且占用CPU时间。占用CPU干什么呢?她会不停的轮询锁的状态,直到资源可用,这就是所谓的活锁;
缺点:线程2会一直使用CPU时间(假如当前系统只有这两个线程在运行),也就意味着不仅浪费了CPU时间,而且还会有频繁的线程上下文切换,对性能影响是很严重的。
当然她的优点是效率高,适合哪种对资源占用时间很短的线程同步。
.NET中为我们提供了两种原子性操作,利用原子操作可以实现一些简单的用户模式锁(如自旋锁)。
- System.Threading.Interlocked:易失构造,它在包含一个简单数据类型的变量上执行原子性的读或写操作。
- Thread.VolatileRead 和 Thread.VolatileWrite:互锁构造,它在包含一个简单数据类型的变量上执行原子性的读和写操作。
内核模式构造
这是针对用户模式的一个补充,先模拟一个内核模式构造的同步流程来理解她的工作方式:
- 线程1请求了临界资源,并在资源门口使用了内核模式构造的锁;
- 线程2请求临界资源时,发现有锁,就会被系统要求睡眠(阻塞),线程2就不会被执行了,也就不会浪费CPU和线程上下文切换了;
- 等待线程1使用完资源后,解锁后会发送一个通知,然后操作系统会把线程2唤醒。假如有多个线程在临界资源门口等待,则会挑选一个唤醒;
看上去是不是非常棒!彻底解决了用户模式构造的缺点,但内核模式也有缺点的:将线程从用户模式切换到内核模式(或相反)导致巨大性能损失。调用线程将从托管代码转换为内核代码,再转回来,会浪费大量CPU时间,同时还伴随着线程上下文切换,因此尽量不要让线程从用户模式转到内核模式。
它的优点就是阻塞线程,不浪费CPU时间,适合那种需要长时间占用资源的线程同步。
内核模式构造的主要有两种方式,以及基于这两种方式的常见的锁:
- 基于事件:如AutoResetEvent、ManualResetEvent
- 基于信号量:如Semaphore
混合线程同步
Lock、SemaphoreSlim、ManualResetEventSlim、Monitor、ReadWriteLockSlim
lock的本质就是使用的Monitor,lock只是一种简化的语法形式,实质的语法形式如下:
1 | bool lockTaken = false; |
Semaphore 信号量
它可以控制对某一段代码或者对某个资源访问的线程的数量,超过这个数量之后,其它的线程就得等待,只有等现在有线程释放了之后,下面的线程才能访问。这个跟锁有相似的功能,只不过不是独占的,它允许一定数量的线程同时访问。
1 | static SemaphoreSlim _sem = new SemaphoreSlim(3); // 我们限制能同时访问的线程数量是3 |
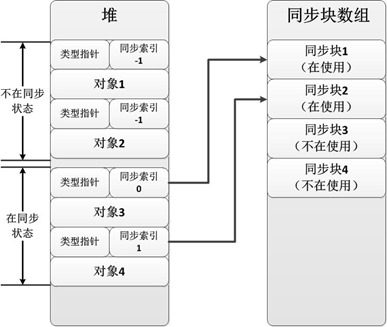
同步索引块是.NET中解决对象同步问题的基本机制,该机制为每个堆内的对象(即引用类型对象实例)分配一个同步索引,她其实是一个地址指针,初始值为-1不指向任何地址。
- 创建一个锁对象Object obj,obj的同步索引块(地址)为-1,不指向任何地址;
- Monitor.Enter(obj),创建或使用一个空闲的同步索引块(如下图中的同步块1),这个才是真正的同步索引块,其内部结构就是一个混合锁的结构,包含线程ID、递归计数、等待线程统计、内核对象等,类似一个混合锁AnotherHybridLock。obj对象(同步索引块AsynBlockIndex)指向该同步块1;
- Exit时,重置为-1,那个同步索引块1可以被重复利用;
Lock关键字
lock 确保当一个线程位于代码的临界区时,另一个线程不进入临界区。如果其他线程试图进入锁定的代码,则它将一直等待(即被阻止),直到该对象被释放。
通常,应避免锁定 public 类型,否则实例将超出代码的控制范围。常见的结构 lock (this)、lock (typeof (MyType)) 和 lock (“myLock”) 违反此准则:
- 如果实例可以被公共访问,将出现 lock (this) 问题。
- 如果 MyType 可以被公共访问,将出现 lock (typeof (MyType)) 问题。
- 由于进程中使用同一字符串的任何其他代码将共享同一个锁,所以出现lock(“myLock”) 问题。
最佳做法是定义 private 对象来锁定, 或 private static 对象变量来保护所有实例所共有的数据。
不要Lock值类型,不要Lock(this),不要Lock(null对象),推荐Lock只读静态对象。
因此,锁对象要求必须为一个引用对象(在堆上)。
多线程使用及线程同步总结
在使用Lock时,关键点就是锁对象了,需要注意以下几个方面:
- 这个对象肯定要是引用类型,值类型可不可呢?值类型可以装箱啊!你觉得可不可以?但也不要用值类型,因为值类型多次装箱后的对象是不同的,会导致无法锁定;
- 不要锁定this,尽量使用一个没有意义的Object对象来锁;
- 不要锁定一个类型对象,因类型对象是全局的;
- 不要锁定一个字符串,因为字符串可能被驻留,不同字符对象可能指向同一个字符串;
- 不要使用[System.Runtime.CompilerServices.MethodImpl(MethodImplOptions.Synchronized)],这个可以使用在方法上面,保证方法同一时刻只能被一个线程调用。她实质上是使用lock的,如果是实例方法,会锁定this,如果是静态方法,则会锁定类型对象
题目答案解析
1. 描述线程与进程的区别?
- 一个应用程序实例是一个进程,一个进程内包含一个或多个线程,线程是进程的一部分;
- 进程之间是相互独立的,他们有各自的私有内存空间和资源,进程内的线程可以共享其所属进程的所有资源;
2. 为什么GUI不支持跨线程访问控件?一般如何解决这个问题?
因为GUI应用程序引入了一个特殊的线程处理模型,为了保证UI控件的线程安全,这个线程处理模型不允许其他子线程跨线程访问UI元素。解决方法还是比较多的,如:
- 利用UI控件提供的方法,Winform是控件的Invoke方法,WPF中是控件的Dispatcher.Invoke方法;
- 使用BackgroundWorker;
- 使用GUI线程处理模型的同步上下文SynchronizationContext来提交UI更新操作
上面几个方式在文中已详细给出。
3. 简述后台线程和前台线程的区别?
应用程序必须运行完所有的前台线程才可以退出,或者主动结束前台线程,不管后台线程是否还在运行,应用程序都会结束;而对于后台线程,应用程序则可以不考虑其是否已经运行完毕而直接退出,所有的后台线程在应用程序退出时都会自动结束。
通过将 Thread.IsBackground 设置为 true,就可以将线程指定为后台线程,主线程就是一个前台线程。
4. 说说常用的锁,lock是一种什么样的锁?
常用的如如SemaphoreSlim、ManualResetEventSlim、Monitor、ReadWriteLockSlim,lock是一个混合锁,其实质是Monitor[‘mɒnɪtə]。
5. lock为什么要锁定一个参数,可不可锁定一个值类型?这个参数有什么要求?
lock的锁对象要求为一个引用类型。她可以锁定值类型,但值类型会被装箱,每次装箱后的对象都不一样,会导致锁定无效。
对于lock锁,锁定的这个对象参数才是关键,这个参数的同步索引块指针会指向一个真正的锁(同步块),这个锁(同步块)会被复用。
6. 多线程和异步有什么关系和区别?
多线程是实现异步的主要方式之一,异步并不等同于多线程。实现异步的方式还有很多,比如利用硬件的特性、使用进程或纤程等。在.NET中就有很多的异步编程支持,比如很多地方都有Begin、End的方法,就是一种异步编程支持,她内部有些是利用多线程,有些是利用硬件的特性来实现的异步编程。
7. 线程池的优点有哪些?又有哪些不足?
优点:减小线程创建和销毁的开销,可以复用线程;也从而减少了线程上下文切换的性能损失;在GC回收时,较少的线程更有利于GC的回收效率。
缺点:线程池无法对一个线程有更多的精确的控制,如了解其运行状态等;不能设置线程的优先级;加入到线程池的任务(方法)不能有返回值;对于需要长期运行的任务就不适合线程池。
8. Mutex和lock有何不同?一般用哪一个作为锁使用更好?
Mutex是一个基于内核模式的互斥锁,支持锁的递归调用,而Lock是一个混合锁,一般建议使用Lock更好,因为lock的性能更好。
9. 下面的代码,调用方法DeadLockTest(20),是否会引起死锁?并说明理由。
1 | public void DeadLockTest(int i) |
不会的,因为lock是一个混合锁,支持锁的递归调用,如果你使用一个ManualResetEvent或AutoResetEvent可能就会发生死锁。
10. 用双检锁实现一个单例模式Singleton。
1 | public static class Singleton<T> where T : class,new() |
11.下面代码输出结果是什么?为什么?如何改进她?
int a = 0;
System.Threading.Tasks.Parallel.For(0, 100000, (i) =>
{
a++;
});
Console.Write(a);
输出结果不稳定,小于等于100000。因为多线程访问,没有使用锁机制,会导致有更新丢失。
改进:
1 | System.Threading.Interlocked.Add(ref a, 1);//正确 |
参考:
https://docs.microsoft.com/zh-cn/dotnet/api/system.threading.autoresetevent?view=netframework-4.7.2